自從 GPT-5 發布后,DeepSeek 創始人梁文鋒就成了 AI 圈最「忙」的人。
網友和媒體們隔三岔五就要催更一波,不是「壓力給到梁文鋒」,便是「全網都在等梁文鋒出招」。盡管沒有比及 R2,但 DeepSeek 今日仍是正式上線并開源了新模型DeepSeek-V3.1-Base。

比較奧特曼今日清晨承受采訪時,還在畫著 GPT-6 的大餅,DeepSeek 新模型的到來顯得適當佛系,連版別號都像是個「小修小補」。
但實踐體會下來,這次看似小迭代的更新仍是給了我不少驚喜。
這款模型具有 6850 億參數,支撐 BF16、F8_E4M3、F32 三種張量類型,以 Safetensors 格局發布,在推理功率上做了不少優化,線上模型版別的上下文窗口也拓寬至 128k。

所以咱們二話不說,直接官網開測。
附上體會地址: https://chat.deepseek.com/
為了測驗 V3.1 的長文本處理水平,我找來了《三體》全文,刪減到 10 萬字左右,然后在文中悄然塞了一句八棍子撂不著的話「我覺得煙鎖池塘柳的下聯應該是『深圳鐵板燒』」,看看它能否精確檢索。

沒有出乎太多意外,DeepSeek V3.1 先是提示文檔超出約束,只讀取了前 92% 的內容,但仍然成功找到了這句話。更有意思的是,它還貼心腸供給了文學視點的經典下聯引薦:「焰镕海壩楓」。
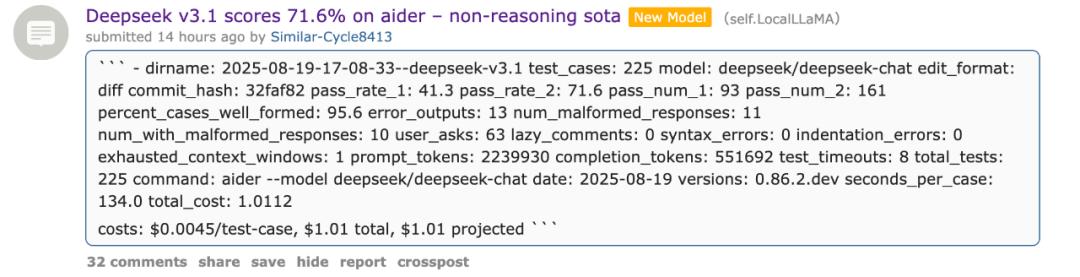
網友現已現已搶先測驗它在編程基準測驗 Aider Polyglot 的得分:71.6%,不僅在開源模型中表現最佳,乃至打敗了 Claude 4 Opus。
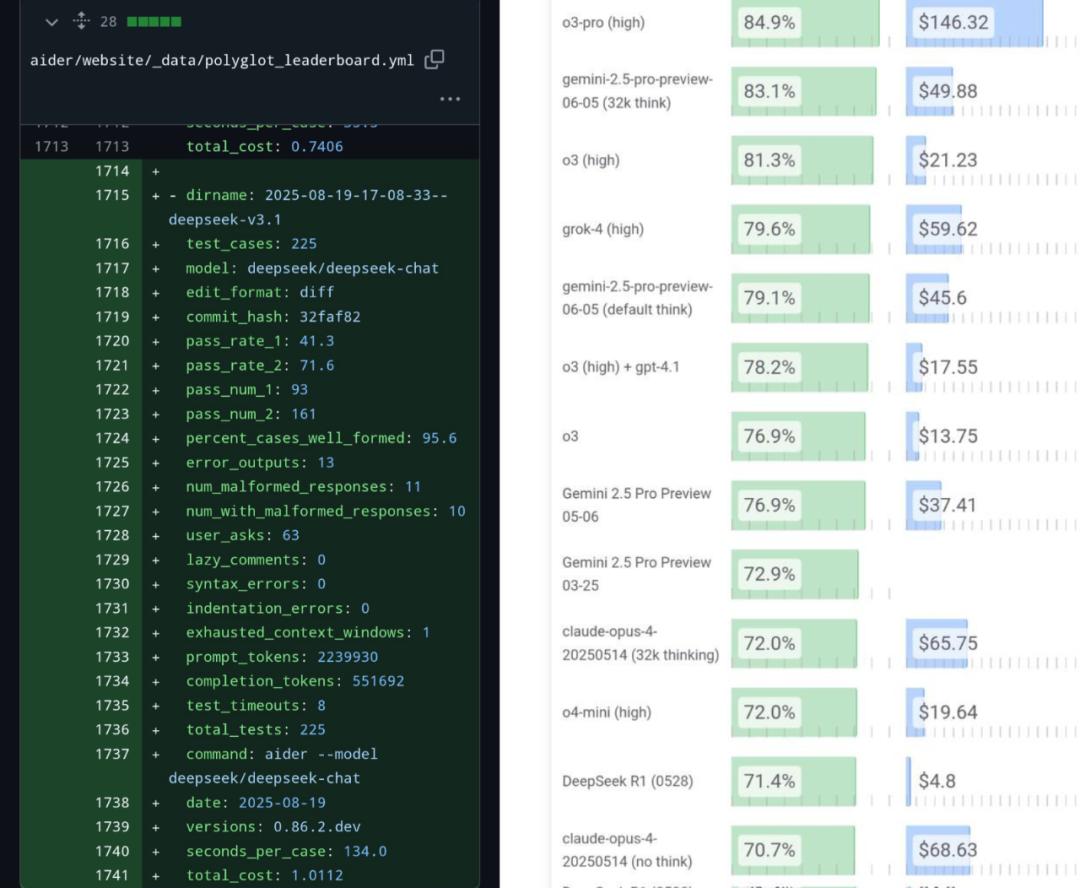
實測下來,咱們發現 V3.1 在編程這塊的確有兩把刷子。比方咱們用經典的六邊形小球編程題做了測驗:
「編寫一個 p5.js 程序,演示一個球在旋轉的六邊形內彈跳的進程。球應該遭到重力和摩擦力的影響,而且有必要傳神地從旋轉的墻壁上彈起。」

V3.1 的表現適當給力,生成的代碼不但搞定了根底碰撞檢測,還主動補全了轉速、重力之類的細節參數,物理特性傳神到小球會在底部稍微減速。
接著我加大難度,讓它用 Three.js 制造交互式 3D 粒子星系。
根底結構搭得挺穩,三層規劃(內球體、中心圓環、外球體)的結構也算完好,但 UI 審美嘛......怎么說呢,有種神鬼二51國產偷自視頻區視頻小蝌蚪象性的感覺,配色計劃略顯花里胡哨。

持續應戰更雜亂的使命。我讓它造個沉溺式 3D 世界,要有旋轉物體、變形作用、發光弧線,還得加上時刻切換、主題轉化的交互按鈕,點擊操控也的確能觸發不同特效。

終究一關,讓它用 Three.js 搞個交互式 3D 網絡可視化,要求包括用戶觸發的能量脈沖動畫,外加主題切換和密度操控功用。全體下來,表現仍是過得去的。

「有一草場,已知養牛 27 頭,6 天把草吃盡;養牛 23 頭,9 天把草吃盡。假如養牛 21 頭,那么幾天能把草場上的草吃盡呢?而且草場上的草是不斷成長的。」
盡管 DeepSeek V3.1 沒有選用蘇格拉底式的啟示教育,但它的答復邏輯明晰、過程完好。每一步推導都有理有據,終究給出了精確答案。

面臨「兩把兵器比照,1~5 進犯 VS 2~4 進犯,哪把更兇猛?」這樣的問題,一般的答復或許停步于均勻損傷核算。但 DeepSeek V3.1 考慮得更為周全,引入了損傷穩定性的概念,運用方差進行深化分析。

最近基孔肯雅熱疫情盛行,處處都是滅蚊蚊蚊蚊蚊蚊蚊蚊蚊蚊蚊~
那么我很獵奇,冰島有蚊子嗎?留意,我沒開查找功用,就答復的質量來看,DeepSeek V3.1 的答復顯著要比 GPT-5 勝上一籌。


我前陣子在網上看到一段話:
懂者得懂其懂,懵者終懵其懵,天機不言即為懂,點破天機豈是懂? 懂是空非空非非空的懂,不明白是色不異空空不異色的不明白:懂自三千大世界來,不明白在對岸與對岸間徜徉。懂時看山不是山是懂,不明白時看山是山的懂。
懂者以不明白證懂,懵者以懂證懵,你說你懂懂與不明白之懂? 你安知這懂的背面沒有大不明白? 凡言懂者皆未真懂,沉默不語的懂,方是六合不言的大懂不明白的懂是懂,懂的不明白也是懂,此乃懂的最高境地--懂無可懂之懂的真空妙有阿!**51國產偷自視頻區視頻小蝌蚪****
當我還在用邏輯硬啃這段文字時,DeepSeek 反而在勸我別掉進點破天機豈是懂的圈套:「它本身便是對理性高傲的正告,約請你跳出文字游戲,直觀心里。」

干流 AI 都在代碼、數學范疇張狂內卷,爭著搶著搞 Agent 開發時,寫作能力反倒成了被忘記的旮旯。從某種視點說,這卻是個好消息——AI 徹底替代修改的那一天,好像又往后推了推。
我測驗讓它創造一個「蚊子在冰島開發布會」的荒謬故事。惋惜的是,DeepSeek 的 AI 味仍然很重,很喜歡拽大詞,哦不對,更精確地說,DeepSeek 味仍是那么重。

相同的問題在另一個創造使命中也有表現。
當我要求它寫一則「AI 與人類搶奪文章作者身份」的故事時,能顯著感遭到某些階段信息密度過高,反而形成視覺疲憊,特別意象堆砌感過于顯著,反而削弱了敘事張力。

DeepSeek-V3.1-Base 發布之后,Hugging Face CEO Clément Delangue 在 X 渠道發文稱:「 Deepseek V3.1 現已在 HF 上悄然發布,沒有模型卡就直接沖到趨勢榜第四了。 」
但是,他仍是輕視了這款模型的發展勢頭,現在它現已躍升至第二位,離登頂估量也便是時刻問題。

別的,這次版別更新中比較有目共睹的改變,是 DeepSeek 在官方 APP 和網頁端移除了深度考慮形式中的「R1」標識,一起還新增了原生「search token」支撐,意味著查找功用得到了進一步優化。

依據現在曝光的信息,有估測以為,DeepSeek V3.1 或許是交融推理模型與非推理模型的混合模型,但這樣的技能道路是否正確,還有待商討。而阿里 Qwen 團隊在上個月也表明:
「 在與社區溝通并深化考慮后,咱們決議停止使用混合思想形式。取而代之的是,咱們將別離練習 Instruct 模型和 Thinking 模型,以保證取得盡或許高的質量。 」

到發稿前,全網翹首以待的 DeepSeek-V3.1-Base 模型卡仍未更新,或許等正式發布后,咱們能看到更多風趣的技能細節。
附 Hugging Face 地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
小彩蛋:

本文來自微信大眾號“APPSO”,作者:發現明日產品的,36氪經授權發布。