
當(dāng)時,大言語模型(LLM)在醫(yī)療、金融、法令等專業(yè)范疇,常因缺少深度常識而體現(xiàn)較差,怎么讓 LLM 在不同特定范疇中發(fā)揮最佳功用,仍是一大應(yīng)戰(zhàn)。
現(xiàn)有干流計劃包含范疇自習(xí)慣預(yù)練習(xí)(DAPT)和檢索增強生成(RAG)。但是,DAPT 需求進行耗時的全參數(shù)練習(xí),且易發(fā)生災(zāi)難性忘記,難以讓多個模型在同一范疇中高效適配;而 RAG 也因貴重的 kNN 查找和更長的上下文,推理推遲大大添加。
并且,因為 RAG 的即插即用特性與 DAPT 的推理功率之間存在固有對立,開發(fā)既能跨模型習(xí)慣,又能在布置時堅持核算功率的處理計劃,仍為空白。
為此,來自上海交通大學(xué)和上海AI Lab 的研討團隊提出了一個“即插即用”的預(yù)練習(xí)回想模塊——“回想解碼器”(Memory Decoder),無需修正原模型參數(shù),即可適配不同尺度模型,完成 LLM 的高效范疇習(xí)慣。

論文鏈接:https://arxiv.org/abs/2508.09874v1
Memory Decoder 的中心立異在于其“即插即用”的特性。經(jīng)過練習(xí)后,單個 Memory Decoder 可無縫集成到任何運用相同 tokenizer 的 LLM 中,而無需進行模型特定調(diào)整或額定練習(xí)。這種規(guī)劃完成了跨不同模型架構(gòu)的即時布置,明顯下降了布置本錢。
試驗成果標(biāo)明,Memory Decoder 可以有用地將各種 Qwen 和 Llama 模型習(xí)慣于生物醫(yī)學(xué)、金融和法令專業(yè)范疇,困惑度均勻下降 6.17%。
架構(gòu)
在預(yù)練習(xí)階段,Memory Decoder 經(jīng)過散布對齊丟失函數(shù),學(xué)習(xí)怎么將其輸出散布與非參數(shù)檢索器生成的散布進行對齊。
在推理階段,Memory Decoder 與根底言語模型并行處理輸入數(shù)據(jù),經(jīng)過插值其散布生成范疇增強型猜測成果,且無需額定的檢索開支。

圖|Memory Decoder 架構(gòu)概覽,在預(yù)練習(xí)階段學(xué)習(xí)仿照非參數(shù)檢索散布,在推理階段無縫集成任何兼容的言語模型,然后消除數(shù)據(jù)存儲保護和 kNN 查找?guī)淼暮怂汩_支。
與傳統(tǒng)根據(jù)單標(biāo)簽方針的言語建模辦法不同,kNN 散布經(jīng)過捕捉范疇內(nèi)合理連續(xù)的多樣性,供給更豐厚的監(jiān)督信號。很多試驗驗證,混合方針函數(shù)能獲得最佳功用。這一研討辦法的中心在于引進散布對齊丟失函數(shù),該函數(shù)經(jīng)過最小化 Memory Decoder 輸出散布與緩存 kNN 散布之間的 KL 散度來完成。

圖|跨范疇習(xí)慣辦法的推理推遲比較
經(jīng)過預(yù)練習(xí)的 Memory Decoder 可以經(jīng)過簡略的插值操作,將任何言語模型與兼容的 tokenizer 適配到方針范疇。
比較其他范疇自習(xí)慣技能,Memory Decoder 僅需對相對較小的 transformer 解碼器進行單次前向傳達,青青草官網(wǎng)在線視頻觀看在推理功率上完成了明顯提高。Memory Decoder 與 LLM 之間的進程通訊開支可經(jīng)過延伸推理時刻來分?jǐn)偅?kNN 查找則會隨數(shù)據(jù)量線性增加。這種核算優(yōu)勢結(jié)合 Memory Decoder 的“模型無關(guān)”規(guī)劃,使其在對功用和功率都至關(guān)重要的出產(chǎn)環(huán)境中具有共同價值。
功用評價
研討團隊評價了 Memory Decoder 在 6 種互補場景下的功用:
- 在 WikiText-103 數(shù)據(jù)集上的言語建模,驗證其在不同規(guī)劃 GPT-2 模型中的適用性;
- 下流使命測驗,驗證范疇習(xí)慣過程中通用才能的保存作用;
- 跨模型習(xí)慣,展現(xiàn)單個 Memory Decoder 在 Qwen 模型(0.5B-72B)帶來的功用提高;
- 跨詞匯習(xí)慣,證明不同 tokenizer 間的高效搬遷才能;
- 常識密集型問答使命,證明 Memory Decoder 在堅持推理才能的一起也可以增強現(xiàn)實回想功用——這是傳統(tǒng)檢索辦法的要害限制;
- 針對特定范疇的下流使命,驗證其在 13 項實在場景基準(zhǔn)測驗中對上下文學(xué)習(xí)才能的堅持。
詳細(xì)如下:
1.WikiText-103 中的言語建模
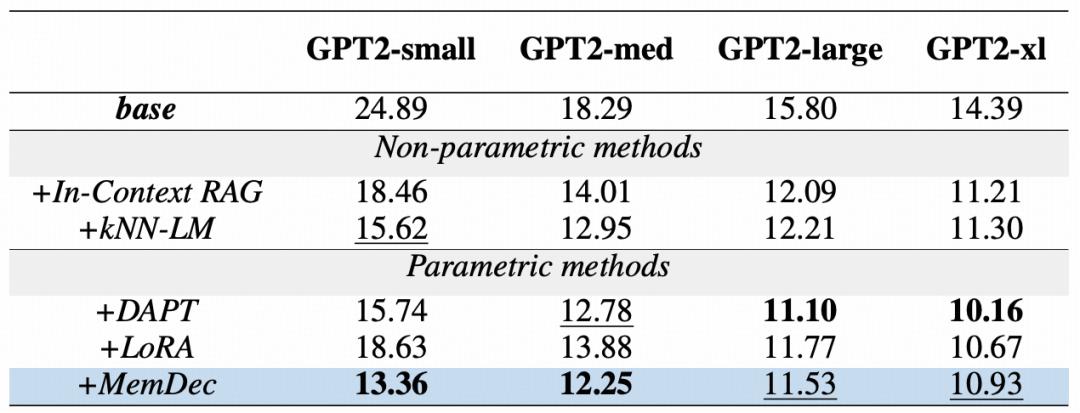
表|GPT2 模型在 WikiText-103 數(shù)據(jù)集上的域習(xí)慣辦法的困惑度比照
上表展現(xiàn)了 Memory Decoder 在一切 GPT2 模型尺度上的有用性。僅需 1.24 億參數(shù)的單個 Memory Decoder,就能明顯提高整個 GPT2 系列模型的功用,展現(xiàn)了其即插即用的優(yōu)勢——不管根底模型規(guī)劃怎么。
即便在使用于更大規(guī)劃的模型時,雖然 DAPT 因為選用全模型更新而具有固有優(yōu)勢,Memory Decoder 仍然堅持著微弱的競爭力,且在不修正任何原始參數(shù)的情況下,可以繼續(xù)逾越其他一切參數(shù)優(yōu)化辦法。
這些成果證明,小參數(shù)解碼器既能有用發(fā)揮非參數(shù)檢索的優(yōu)勢,又能大幅下降核算開支。
2.下流功用

表|在情感剖析、文本包含和文本分類等 9 種不同 NLP 使命上的功用體現(xiàn)
如上表,在零樣本評價環(huán)境中,Memory Decoder 在增強范疇習(xí)慣的一起堅持通用言語功用的才能。與在多個使命中呈現(xiàn)災(zāi)難性忘記的 DAPT 不同,Memory Decoder 在一切評價使命中,均能堅持或提高功用。
這一辦法在悉數(shù) 9 項使命中均獲得最高均勻分。不只逾越了根底模型、kNN-LM 和 LoRA,還在 CB、RTE 等文本包含使命中展現(xiàn)出共同優(yōu)勢。
這些成果驗證了這一架構(gòu)的中心優(yōu)勢:在堅持原始模型參數(shù)完好的一起,Memory Decoder 經(jīng)過融入范疇常識,完成了無需獻身通用才能的范疇習(xí)慣。
3.跨模型習(xí)慣
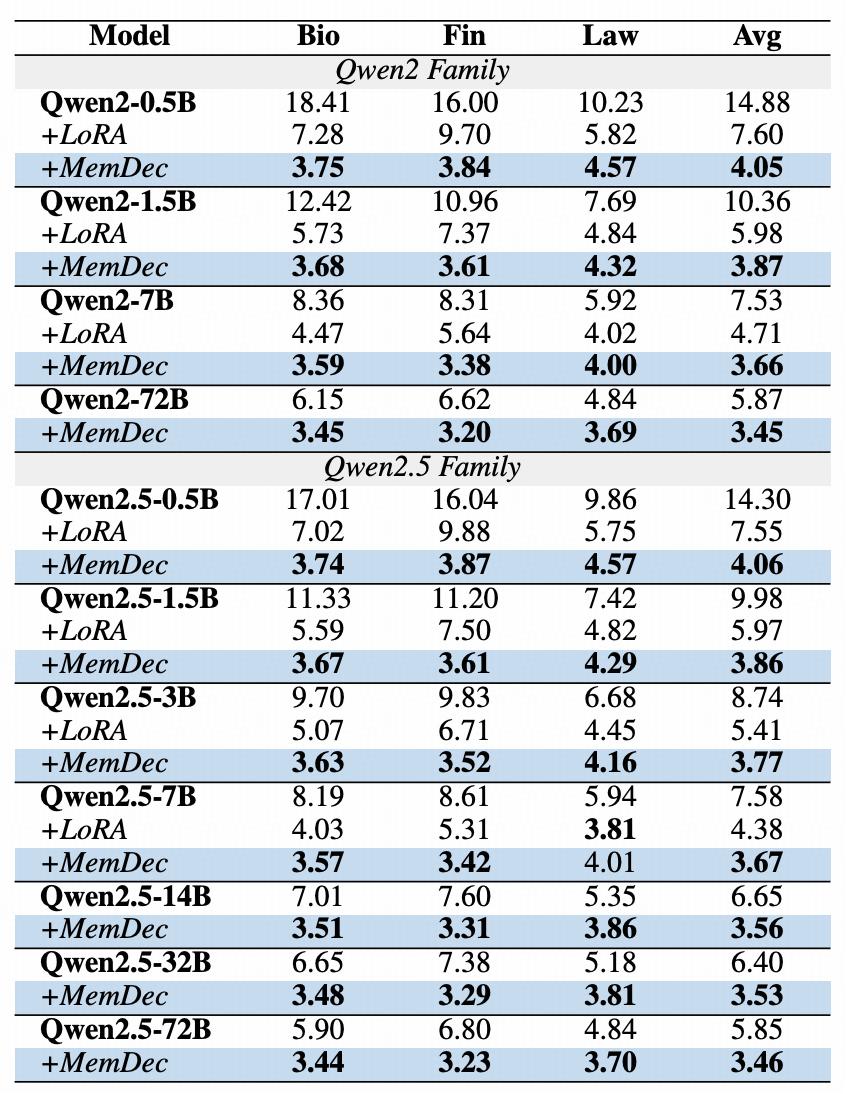
表|三個專業(yè)范疇的跨模型習(xí)慣成果
上表展現(xiàn)出 Memory Decoder 在不同模型規(guī)劃和架構(gòu)上的即插即用才能。單個Memory Decoder (0.5B 參數(shù))在 Qwen2 和 Qwen2.5 系列的一切模型中均能繼續(xù)提高功用。單一預(yù)練習(xí)回想組件可提高同享同一 tokenizer 的多個模型,完成高效的范疇習(xí)慣擴展,使得不同尺度模型都能繼續(xù)逾越現(xiàn)有辦法。
4.跨詞匯習(xí)慣

表|跨模型常識搬遷作用明顯
上表展現(xiàn)了 Memory Decoder 在不同 tokenizer 和模型架構(gòu)下的泛化才能。經(jīng)過僅從頭初始化根據(jù) Qwen2.5 練習(xí)的 Memory Decoder 的嵌入層和言語模型頭,團隊成功將其適配到 Llama 模型宗族,且僅需原練習(xí)預(yù)算的 10%。這種高效的搬遷才能使一切 Llama 變體都完成了功用提高。
關(guān)于 Llama3-8B,Memory Decoder 在生物醫(yī)學(xué)和金融范疇下降了約 50% 困惑度。相似的改善也延伸至 Llama3.1 和 Llama3.2,他們的辦法在生物醫(yī)學(xué)和金融范疇一直優(yōu)于 LoRA,但在法青青草官網(wǎng)在線視頻觀看令文本范疇仍有改善空間。
這些發(fā)現(xiàn)標(biāo)明,Memory Decoder 的通用性逾越了單一 tokenizer 宗族,證明了從單一架構(gòu)中習(xí)得的范疇常識可以高效搬遷至其他架構(gòu),且僅需求少數(shù)額定練習(xí)。這一才能擴展了咱們辦法的實踐使用價值,為在多樣化的模型生態(tài)系統(tǒng)中完成范疇習(xí)慣供給了簡化的途徑。
5.常識密集型推理使命

表|常識密集型問答使命的功用體現(xiàn)
雖然 RAG 辦法在提高現(xiàn)實回想方面體現(xiàn)出色,但在一起需求常識檢索與雜亂推理的使命中卻常常體現(xiàn)較差。從前研討標(biāo)明,雖然 kNN-LM 能從相關(guān)維基百科語料庫中檢索信息,但在常識密集型問答使命中反而或許影響功用體現(xiàn)。
如上表所示,Memory Decoder 在兩項基準(zhǔn)測驗中成功增強了模型獲取現(xiàn)實性常識的才能,一起堅持了推理才能,處理了傳統(tǒng)檢索辦法的根本性限制。
試驗成果標(biāo)明,經(jīng)過學(xué)習(xí)內(nèi)化檢索形式而非依靠顯式推理,Memory Decoder 在堅持處理雜亂多跳問題所需組合推理才能的一起,還能充分利用擴展后的常識拜訪優(yōu)勢。
缺乏
以上成果證明,Memory Decoder 保存了檢索辦法的回想才能,又兼具參數(shù)化辦法的高效性和泛化優(yōu)勢。
Memory Decoder 的多功用性和高效性,使得它能無縫增強任何同享相同 tokenizer 的模型,且只需少數(shù)額定練習(xí)即可適配不同 tokenizer 和架構(gòu)的模型。這種才能使得跨模型宗族的高效范疇習(xí)慣成為或許,大幅減少了專用模型開發(fā)一般所需的資源。
可以說,Memory Decoder 創(chuàng)始了范疇自習(xí)慣的新范式,并從根本上從頭界說了怎么為特定范疇定制言語模型。經(jīng)過預(yù)練習(xí)回想組件將范疇專業(yè)常識與模型架構(gòu)解耦,這一辦法構(gòu)建了一個更模塊化、高效且易于拜訪的結(jié)構(gòu),然后可以提高言語模型在專業(yè)范疇的體現(xiàn)。
但是,Memory Decoder 也并非完美,仍然存在一些限制性。
例如,在預(yù)練習(xí)階段,Memory Decoder 需求經(jīng)過 KV 數(shù)據(jù)存儲進行查找,以獲取 kNN 散布作為練習(xí)信號,這會發(fā)生核算開支。雖然該本錢僅在每個范疇中發(fā)生一次,且可分?jǐn)傊烈磺辛?xí)慣模型,但這仍是整個流程中的瓶頸。
此外,雖然跨 tokenizer 習(xí)慣比較從頭練習(xí)所需參數(shù)更新較少,但仍需進行部分參數(shù)調(diào)整以對齊嵌入空間,阻止了真實「零樣本跨架構(gòu)搬遷」的完成。
本文來自微信大眾號“學(xué)術(shù)頭條”,作者:小瑜,36氪經(jīng)授權(quán)發(fā)布。