幾個月前,愛范兒在一臺 M3 Ultra 的 Mac Studio 上,成功布置了 671B 的 DeepSeek 的本地大模型(4-bit 量化版)。
而假如咱們搞來 4 臺頂配 Mac Studio……
- 每一臺都是 M3 Ultra
- 512GB 一致內存
- 819GB/s 內存帶寬
- 80 核 GPU
- 80Gbps 雷靂 5 雙向傳輸……
把這四頭猛獸,經過開源東西串聯成一個「桌面級 AI 集群」——能否把本地推理的天花板再舉高一個維度?
這也是來自英國創業公司 Exo Labs 正測驗處理的問題。而愛范兒成為了第一批見到這個全新處理計劃的我國媒體之一。

「地主家也沒有余糧」
你可能會認為,像牛津這樣的尖端大學必定 GPU 多得用不完,但其實徹底不是這樣。
Exo Labs 創始人 Alex 和 Seth 結業于牛津大學——即便在這樣的頂尖高校做研討,想要運用 GPU 集群也需求提早數月排隊,一次只能請求一張卡,流程綿長而低效。
( 甭說牛津大學了,就連美國的國家試驗室體系,具有的超算集群算力也相同需求預定排隊。 )
Alex 和 Seth 發現了一個現象:其時 AI 根底設施的高度集中化,使得個人研討者和小型團隊被邊緣化。
為了處理問題,他們在上一年 7 月啟動了第一次試驗,串聯了手頭上的兩臺 MacBook Pro,然后跑通了 LLaMA 模型。盡管功能有限,每秒只能輸出 3 個 token,但現已足以驗證 Apple Silicon 架構用于 AI 分布式推理的可行性。
更重要的是,盡管 LMStudio 等本地跑大模型的根底設施處理計劃現已比較遍及了,但串聯多臺消費級電腦——組成集群——相關計劃在其時依然歸于「不知道水域」。
而這個小團隊的作業,也被蘋果留意到了。

MacBook Pro 的算力終究是有限的,而二人集群化 Mac 電腦的作業,在本年 3 月迎來了一個要害的轉折點:蘋果發布了 M3 Ultra 頂配處理器版別的 Mac Studio。
512GB 一致內存、819GB/s 的內存帶寬、80 核 GPU,再加上 Thunderbolt 5 的 80Gbps 雙向傳輸才能——真實強有力的,足以運轉 2025 上半年滿血版大模型的本地 AI 集群,總算從抱負變成了實踐。
一起跑兩個 670 蘋果種子在線播放億參數大模型是什么體會?
4 臺頂配 M3 Ultra 的 Mac Studio 經過 Thunderbolt 5 串聯后,賬面數據適當驚人:
- 128 核 CPU(32×4)
- 240 個 GPU 中心(80×4)
- 2TB 一致內存(512GB×4)
- 總內存帶寬超越 3TB/s
這樣的組合,功能現已稱得上是一臺小型超算了,但從體積上依然(牽強)可歸到「家用級」。
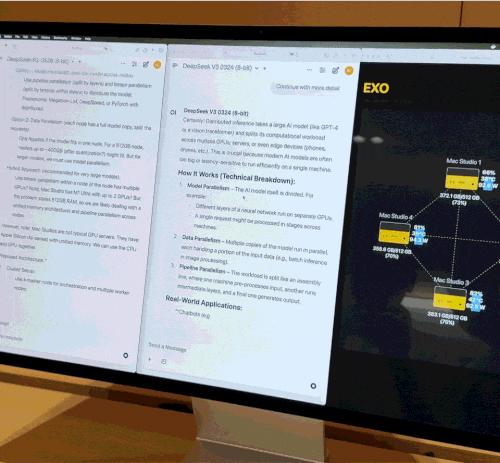
但硬件僅僅根底,真實發揮效能的要害是 Exo Labs 開發的分布式模型調度渠道 Exo V2。Exo V2 會依據內存與帶寬狀況將模型主動拆分,布置在最合適的節點上。
Exo Labs 和蘋果在現場供給了 Exo V2 的 demo,向愛范兒展現了以下中心才能:
大模型加載:8-bit 量化后的 DeepSeek,完好載入需求高達 700GB 內存,單臺 Mac Studio 無力承當。而 Exo 的軟件會將模型拆分布置到 2 臺 Mac Studio 上完結加載。激活后,它的流式輸出「打字速度」根本上超越了人的閱覽速度。
并行推理:在 DeepSeek V3 仍在兩臺頂配 Mac Studio 上跑著的一起,又加載了相同 670 億參數的 DeepSeek R1。體系立行將 R1 分配到剩下的兩臺 Mac Studio,完結兩個大模型并行推理,支撐多用戶一起發問。
私有文檔 RAG 問答:拖入公司財報 PDF,模型在本地完結常識嵌入與問答,不依賴任何云端資源,數據徹底私有可控。
輕量微調:若企業有數千份內部資料,可經過 QLoRA + LoRA 技能進行本地微調。假如只用單臺 Mac Studio,微調的耗時依然長達數日,但 Exo 的集群調度才能,使得練習任務可線性加快,大幅縮短時刻本錢。
巨大的本錢差異
愛范兒在現場后臺調查拓撲圖發現:即便 4 臺機器一起處于高負載狀況,整套體系功耗一直控制在 400W 以內,運轉簡直無電扇噪音。
要在傳統服務器計劃中完結平等功能,至少需求布置 20 張 A100 顯卡,服務器加網絡設備本錢超 200 萬人民幣,功耗達數千瓦,還需獨立機房與制冷體系。
蘋果種子在線播放——就這樣,蘋果 M 芯片在 AI 大模型的浪潮中,意外地找到了一個新的定位。的確令人沒想到。

Exo Labs 根據 M3 Ultra Mac Studio 開發的這個套組,起價格 32999 元,裝備 96GB 一致內存。而 512GB 的頂配版別,更是價格不菲。
但從技能視點來看,一致內存架構帶來的優勢是革命性的。
在規劃 M 芯片之初,蘋果更多是為節能、高效的個人創造而生。但一致內存、高帶寬 GPU、Thunderbolt 多路徑聚合等特性,反而十分合適 AI 本地推理這件事,盡管意料之外,卻又在情理之中。
傳統 GPU,即便是最高端的作業站卡,顯存一般也只要 96GB。而蘋果的一致內存讓 CPU 和 GPU 同享同一塊高帶寬內存,避免了數據在不同存儲層級之間的頻頻轉移,這對大模型推理來說含義嚴重。
當然,EXO 這套計劃也有顯著的定位差異。它不是為了與 H100 正面對立,不是為了練習下一代 GPT,而是為了處理實踐的使用問題:運轉自己的模型,維護自己的數據,進行必要的微調優化。
假如說 H100 是金字塔頂的王者,而 Mac Studio 正在成為中小團隊手中的瑞士軍刀。
本文來自微信大眾號“愛范兒”(ID:ifanr),作者:喬納森何,36氪經授權發布。