我國自研國際模型Matrix-3D只需單張圖就能生成可自在探究的3D國際,不只作用對標李飛飛的World Labs,并且還能完結更大規劃的探究空間,首要進入AI了解國際的前沿范疇。
一花一國際,一葉一菩提。
千百年來,人類只能憑幻想勾勒圖畫之外的國際,夢境與實際之間一直隔著一層不行觸及的紗幕。
而今日,當AI的力氣被無限延伸,這層紗幕總算被揭開——
Matrix-3D,一個實在從「一圖生萬境」的國際模型!
它不僅僅昆侖萬維榜首款,也是榜首首款全自研國際模型「Matrix-Zero」的全新晉級。
進化后的國際模型Matrix-3D,可以從一張山間草地的相片動身,發明出風吹草動、遠山崎嶇的全景景色。


從現代城市的一角動身,它能「腦補」出畫面之外,富貴的大街和大廈。


現在,咱們不再需求多個視圖,也不再局限于部分透視,而是實在完結了幾許結構準確、可以360°自在周游的3D國際。
值得一提的是,本周仍是昆侖萬維如火如荼的AI技能發布周,而Matrix-3D便是第二個進場的模型。
應戰空間智能的中心痛點
大模型賽道卷了兩年,誰都在張望,下一個破局的方向在何方。
在這之中,李飛飛僅用3個月就完結10億估值的World Labs或許能證明:具有空間智能的國際模型正是AI了解國際的下一個前沿。
最近,谷歌發布的Genie 3再次讓所有人對「國際模型」充溢等待,它能以每秒20-24幀速度,實時生成720p畫面,還能持續數分鐘共同性。

作為探究,昆侖萬維也在本年2月時發布了自研的Matrix-Zero國際模型:
- 它不只能將用戶輸入的圖片轉化為可自在探究的實在合理的3D場景;
- 并且還能依據用戶輸入實時生成互動視頻作用。

而這次全新發布的Matrix-3D,初次具有了「從一圖入實境」的構建才能,讓國際模型再次得到了進化:
- 場景大局共同:支撐360°自在視角閱讀,幾許結構準確、遮擋聯系天然,紋路風格共同。
- 生成場景規劃大:與現有場景生成辦法比較,支撐更大規劃的、可360度自在探究的場景生成
- 生成高度可控:一起支撐文本和圖畫輸入,成果與輸入高度匹配,支撐自定義規劃與無限擴展。
- 泛化才能強:依據自研3D數據與視頻模型先驗,可生成豐厚多樣的高質量場景。
- 生成速度快:首個前饋全景3D場景生成模型,可快速生成高質量3D場景。

技能陳述:https://github.com/SkyworkAI/Matrix-3D/blob/main/asset/report.pdf
項目主頁:https://matrix-3d.github.io/
Github:https://github.com/SkyworkAI/Matrix-3D
Hugging Face:https://huggingface.co/Skywork/Matrix-3D
接下來,咱們就來直觀感受一下,Matrix-3D的「威力」吧。
畫面共同性
首要,不管是生成的內容仍是色彩,都能做到共同共同。
其次,在視角上,Matrix-3D可以支撐360°的自在環視。
一座有草房頂的房子,風車,以及延伸至地平線遠端的花田的動漫風格村莊,極為精密,暖光,舒適的氣氛。


此外,物體之間的幾許和遮擋聯系,也能契合物理規律。
一幅印象派風格的冬日景色,包括山脈、湖泊、小屋、樹木和積雪,以藍色調為主,筆觸質感豐厚,氣氛安靜,高分辨率,色彩鮮明。

Matrix-3D生成的全景視頻如下:

而終究的3D場景烘托成果長這樣:

一個方塊像素化的景象,包括山脈、樹木、水體、天空、云朵,相似《我的國際》風格,高分辨率,色彩鮮艷,紋路細節豐厚,氣氛安靜。


精準操控
3D國際中,咱們的視角通常會為所欲為地沿著不同途徑,向各式各樣的方向移動。

針對這些不同的軌道,亞洲AV男人的天堂在線Matrix-3D可以生成與之對應的3D場景。

比方,沿著S形的彎折前行:

或許,向右前方移動:

大規劃移動
比照李飛飛World Labs辦法,Matrix-3D支撐更大規劃的移動。

可以看到,在World Labs發布的視頻中,「咱們」剛走兩步,就碰到鴻溝了。

相似的,Hunyuan World 1.0在邊際的生成上也存在問題。

比較之下,Matrix-3D「生成」的3D國際動態規劃更大,視角更豐厚,規劃更廣。

無限續寫
發明的含義就在于,咱們可以依據已知來描繪「不知道」。
Matrix-3D生成一段場景后,可以答運用戶在此根底上對場景進行擴寫。
比方一開端是一張靜態圖片,描繪了一座建在冰川上的未來研討基地,配有發光穹頂和先進機械,四周環繞著冰封景象,具有科幻美學風格,畫面極為詳盡精巧。

很快,Matrix-3D就依據圖片烘托出了首段視頻。
可以看到,畫面鏡頭從圖片開端慢慢前移,然后半途360°旋轉回正。

可是,假如咱們想持續知道「前路怎么」呢?
Matrix-3D可以依據現已生成的全景視頻持續完結續寫,可以看到畫面跟著鏡頭持續前移,終究進入新的場景。

快速場景重建&精密場景重建
為了歸納考慮生成速度和質量,Matrix-3D有兩套場景生成結構——看中速度的「全景前饋重建」,以及看中質量的「3DGS優化」。
舉個栗子,這是一張描繪河道的圖片。

假如便是想要快速生成,那么全景前饋重建只需不到10秒,即可給出一個可360°觀看的3D場景。

但假如期望得到更好的生成作用,就可以運用3DGS優化,讓終究的場景既詳盡又準確,看上去就像實在拍照的相同。

解密Matrix-3D中心技能
假如說經過30年開展的互聯網國際為當下大模型年代供給了滿足「優質」的練習數據。
那么3D場景數據的稀缺性,也正是現在限制空間智能、3D場景生成的重要原因之一。
為了獲取3D數據,現在一種干流的研討辦法是運用圖畫生成模型或許視頻生成模型,作為三維生成的先驗。
但這類辦法存在一個根本性的缺點:
因為練習進程首要依據透視圖(Perspective View)進行,模型只能學習到部分視角下的有限空間結構。
一旦用戶視角超出練習數據所掩蓋的規劃,場景就會呈現顯著的「鴻溝效應」或「斷層」。
如下圖所示,這種不接連性會嚴重破壞用戶的沉溺感,直接影響VR/AR等需求自在視角探究的下流運用體會。
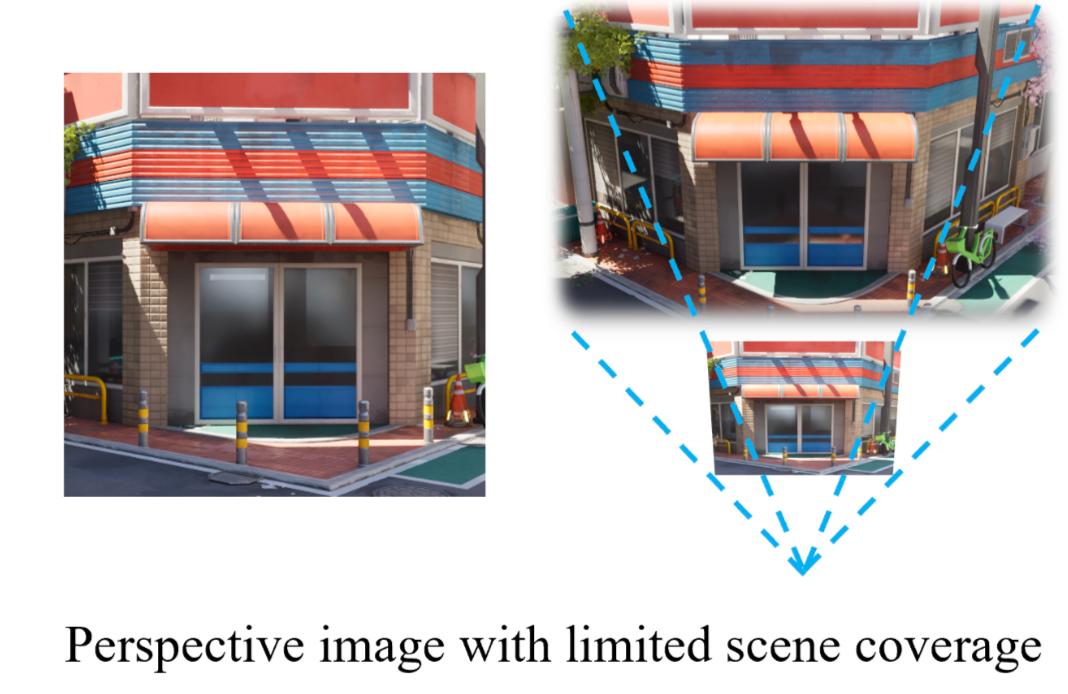
為了完結恣意地址、恣意視點的自在視角閱讀,Matrix-3D引入了全景圖畫(Panoramic Images)作為場景生成的中心表達形式。
與傳統透視圖比較,全景圖具有更全面的空間感知才能——
它可以掩蓋360°水平視角和180°筆直視角,簡直包括了人眼可見的悉數方向,如下圖所示,用戶可以從恣意視點對場景進行調查與探究。

更進一步,將多個地址的全景圖次序拼接,即可構建出一段接連的全景視頻(Panoramic Video)。
這種結構不只保留了各個調查點的空間信息,也為3D場景重建供給了足夠的視覺頭緒,相當于以二維辦法完好記錄了三維國際的骨架與細節。
這為后續的3D國際生成奠定了數據根底,也極大前進了下流運用(如VR/AR)的沉溺式體會質量。
確認運用全景視頻作為中心表達后,Matrix-3D規劃了三個中心模塊來完結3D國際生成:
- 全景圖生成模塊:經過LoRA微調,從文本或透視圖生成高質量全景圖;
- 可控全景視頻生成模塊:結合用戶設定的軌道和規劃,生成接連全景視頻;
- 3D場景生成模塊:從全景視頻解碼出完好3D場景,支撐自在視角探究。
Matrix-Pano數據集
每一個空間智能問題,終究仍是要回歸到數據集。
搜集實在國際的3D場景數據依然本錢昂揚,可是現在3D場景數據集存在規劃小、視角不全、質量參差、缺少精準相機/幾許標示等問題。
所以,昆侖萬維提出了Matrix-Pano數據集——這是一個依據Unreal Engine構建可擴展的全景視頻數據集,專為生成高質量、可探究的全景視頻而規劃。

Matrix-Pano數據集具有以下特色:
- 場景環境多樣:包括11.6萬條全景視頻、2200萬幀畫面,掩蓋504個高質量室內外場景,多種氣候與光照條件。
- 軌道生成智能高效:依據Navigation Mesh與Delaunay三角剖分,結合Dijkstra途徑規劃與Hermite曲線滑潤,主動生成天然連亞洲AV男人的天堂在線接的探究軌道。
- 高仿真碰撞檢測:經過鴻溝框署理,實時除掉穿模或幾許剪切,保證運動軌道物理合理。
- 工業級相機操控:交融多級滑潤與PID操控,完結相機方位與旋轉的精準解耦,生成安穩流通的視頻序列及高質量標示。
- 敞開同享:中心子集將向學術界開源,助力3D生成和空間智能范疇研討。

一起,Matrix-3D的全景視頻生成成果在全景視頻生成評測集上也取得了最好的生成質量。
此外,Matrix-3D辦法在生成成果的視覺質量和相機可控性層面都優于現有辦法。
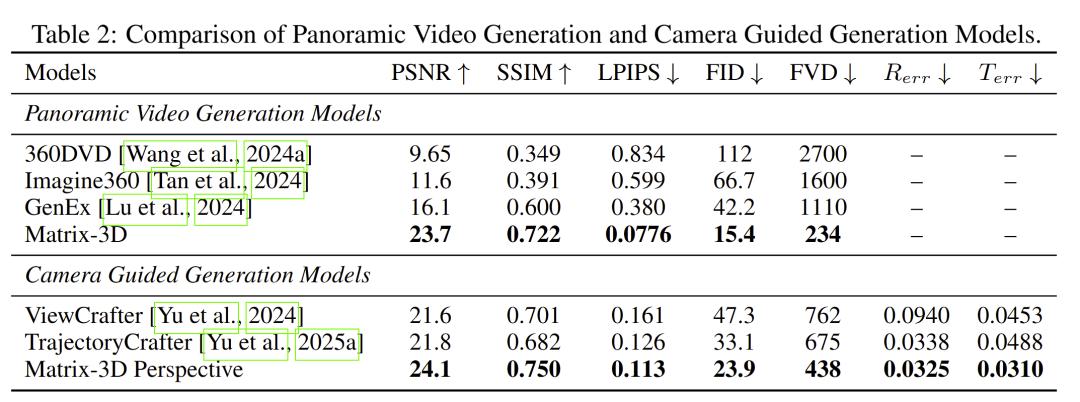

不同辦法生成全景視頻不一起刻比照圖,其間Matrix-3D辦法生成視頻的質量更高、共同性更強(下方小圖為四方向透視圖)
軌道引導的可控全景視頻生成
軌道引導是打破操控性與3D視覺質量的關鍵技能。
所以,首要問題是怎么構建軌道引導?

·Initial Panorama with depth:輸入為帶深度的全景圖,供給根本的空間信息
·Trajectory guidance from point cloud:依據點云的軌道引導
·Trajectory guidance from mesh:依據三角網格的軌道引導辦法
Matrix-3D依據輸入的全景圖畫與深度圖構建三維網格,并結合預設相機軌道生成引導視頻序列。
體系經過深度變化檢測遮擋區域,符號不行見像素并除掉其對應極點,保證遮擋聯系明晰準確。
每一幀引導圖畫都配有可見性掩碼,用于準確操控模型輸入。
與傳統點云烘托比較,該辦法有用緩解摩爾紋和遮擋過錯,前進了幾許共同性和生成質量。
處理了軌道引導,就可以進行全景視頻生成。
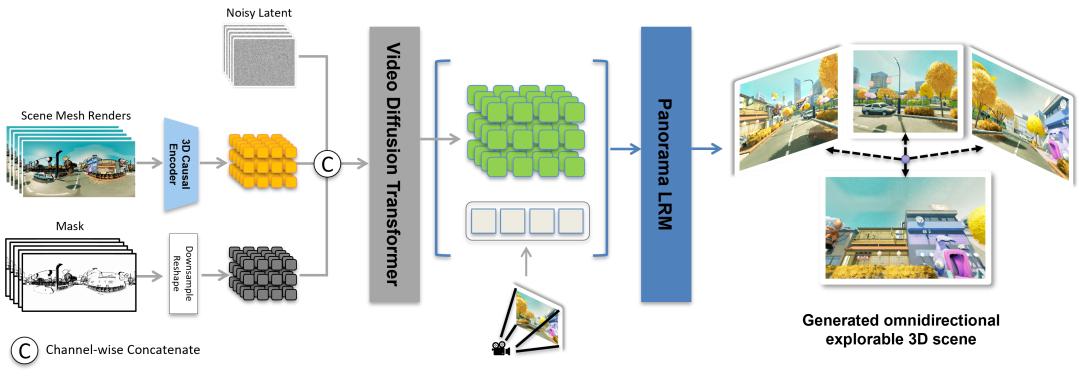
Matrix-3D經過一套「全景烘托+視頻分散」的流程,完結從2D全景圖生成可自在探究的3D國際:
- 流程最左邊為輸入的全景烘托圖(Scene Mesh Renders)和遮擋掩碼(Mask),包括幾許結構和可見性信息;
- 圖畫經3D Causal Encoder編碼,遮擋掩碼下采樣后與其進行通道級拼接;
- 將交融特征輸入Video Diffusion Transformer,在時刻維度組成連接的視頻表明;
3D國際生成:從視頻到可探究三維國際
有了數據,也有了軌道引導的可控全景視頻。
那怎么將全景視頻復原為可自在探究的高質量3D場景呢?
Matrix-3D供給兩種計劃,將全景視頻復原為可自在探究的高質量3D場景:
1. 優化式三維重建:尋求極致畫質
經過預算全景視頻深度并結合相機軌道生成點云,作為三維高斯烘托(3DGS)的根底輸入。
進一步引入超分辨率前進視頻質量,并將全景圖裁剪為12個透視視角,完結高精度3D重建。
適用于對細節要求極高的場景,如虛擬仿真與高保真復原。
2. 前饋三維重建:主打高效快速
為了前進功率,直接從視頻潛變量猜測3DGS表達,明顯下降計算本錢。
經過Transformer+DPT解碼器猜測色彩、深度、尺度、透明度等特點,并結合Plücker編碼精準建模相機姿勢。
選用專為全景圖規劃的CUDA光柵器完結無需多視角的高效烘托。
練習時選用兩階段戰略,先引導模型學習幾許,再優化實在烘托作用,統籌準確性與泛化才能。

最左邊輸入為視頻潛變量+相機編碼。
上支路:對視頻潛變量進行 2D 卷積提取特征;下支路:對相機姿勢(如 Plücker 編碼)進行3D卷積處理,提取時空結構信息。
然后進行特征交融+Transformer 編碼,兩路特征拼接后送入多層Transformer進行大局建模,輸出空間共同的語義表達。
終究是分支解碼,榜首分支猜測深度圖,為重建供給幾許根底;第二分支猜測3DGS的其他特點:色彩、尺度、透明度、旋轉方向等。
終究生成可自在視角探究的全景3D場景,具有實在感強、幾許共同性好的空間體會。
運用遠景
Matrix-3D作為3D國際生成的重要里程碑,將在多個范疇廣泛運用:
游戲與影視制造:快速生成高質量3D場景,助力游戲開發與虛擬拍照,前進沉溺感并明顯下降制造本錢。

具身智能:構建可控模仿環境,用于機器人練習與主動駕駛測驗,前進體系的安全性與泛化才能。

虛擬實際:生成可360°自在探究的沉溺式虛擬空間,為用戶帶來實在可感的交互體會。

這些運用場景展現了Matrix-3D技能在不同范疇中的重要性和多樣性。跟著技能的前進,這些運用將持續開展并帶來更多立異。
從「一圖生萬境」到「無限國際皆可構建」,Matrix-3D 不僅僅一項3D生成技能的打破,更是AI邁向空間智能年代的宣言。
它標志著——AI不再僅僅「解讀」圖畫,而是實在可以「走進」國際;不再僅僅「設想」場景,而是實在具有「發明」實際的力氣。
未來,幻想力將成為探究國際的僅有鴻溝。
而Matrix-3D,正在讓這道鴻溝完全消失。
本文來自微信大眾號“新智元”,作者:定慧 好困 ,36氪經授權發布。