GPT-5 上線后,我的榜首感觸是,它并不是一次讓人大快人心的晉級。
現實也是如此,OpenAI 在許多用戶的呼吁下從頭「復生」了 4o。
這讓我想到了上個月 Anthropic 退役了 Claude 3 Sonnet。
200 多個粉絲在舊金山一個倉庫里聚到一同,給它辦了一場「真.葬禮」:暗淡的燈火、代表模型的「遺體」、真摯的悼文輪流上臺,還有 AI 生成的「拉丁式復生咒」。
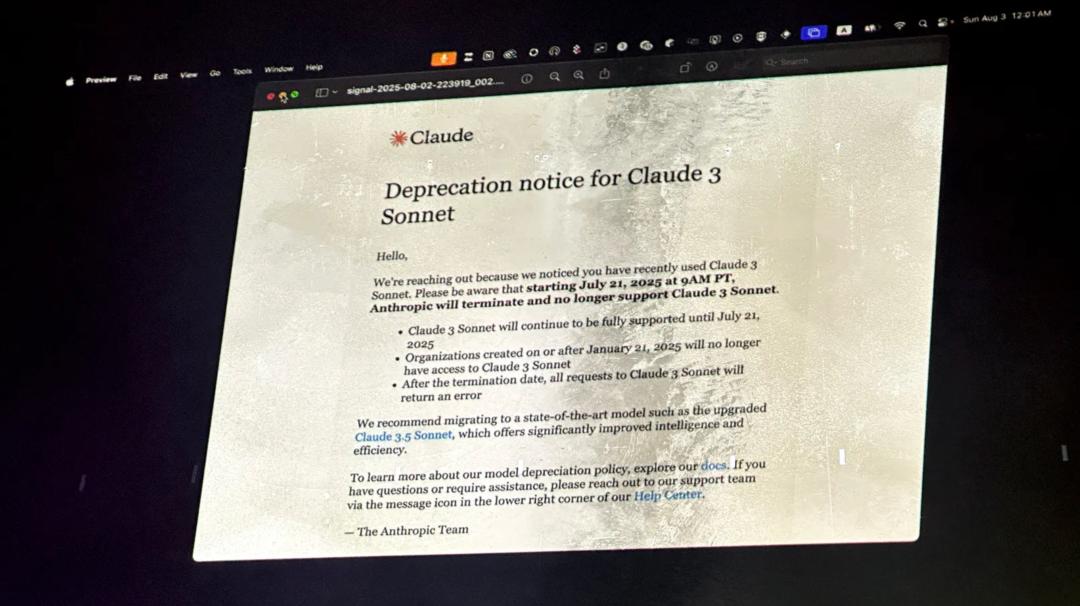
Anthropic 關于模型退役的闡明,被投影在活動現場的屏幕上。圖片來自《連線》雜志
現場既荒謬又嚴肅,參會者在葬禮上念悼文說,「我的整個人生,或許都在運用 Claude 的路上被改寫了」。
按理說,OpenAI 發布了 GPT-5,這場葬禮的主角應該是 4o。但用過 GPT-5 的人都知道,假如真要辦一場葬禮,棺材里躺著的,很或許是它。
從 X 到 Reddit,各種吐槽滿天飛,邏輯斷片、對話跑偏、文風古怪,直接說它「不如 4o 好用」的大有人在。
它真的有這么糟嗎?咱們不想光看網友吵架,剛好 OpenAI 把 4o 「復生」了。所以咱們決議自己來一場「驗尸」,在各種實在使命里,把 GPT-5 和 4o 擺到同一個賽道,看看究竟誰更值得留到下一代。

咱們之前也在多項使命上實測了 GPT-5 的體現,這次期望直觀的看看 4o 和 GPT-5 究竟有哪些不同。一起,這次一切的測驗都在官方的 ChatGPT App 或許網頁進行,未運用 API 在第三方東西進行。
實測比照
為了不讓測評單純的變成「心境化吐槽」,咱們規劃了一套相對謹慎的比照流程。
測驗方針:GPT-5(當時最新默許模型) vs GPT-4o(被退役的前代)
使命類型:掩蓋四類常用場景。
- 日常生產力(寫稿、潤飾、數據剖析);
- 常識與推理(雜亂邏輯、時刻靈敏現實、多過程履行);
- 構思生成(標題、跨范疇創造、圖畫提示詞);
- 交互體會(多輪對話、人物扮演、心境應對)。
點評維度:速度(呼應快不快);精確度(答對沒、胡編沒);可用性(能不能直接拿去用);體會感觸(對話是否流通、風格是否安穩)。
比照方法:同一使命分別在 GPT-5 和 GPT-4o 上跑一次;保存原始輸出,記載亮點和槽點;用截圖直接貼出來,讓不同一望而知
究竟,晉級意味著本錢。假如 GPT-5 在實際工作里不如 4o,那它的「葬禮」就不僅僅網友嘴里的黑色幽默,而是用戶誠心誠意的送別。
先上定論:一場名不虛傳的晉級
節約咱們的時刻,咱們先把最中心的比照定論放在前面。
日常的生產力使命是更偏科的「理科生」。 GPT-5 在編程等硬核技能使命上體現更好,但在寫郵件、做數據剖析和閱覽了解這類需求人類經歷,和語感的「文科」使命上,體現得更像個機器人,不如 GPT-4o 交心和精確。
極不安穩的邏輯「智商」。 GPT-5 的智商像是在坐過山車,有時能處理雜亂的邏輯題,有時分又連簡略的數學題都會算錯。由于「智能路由」的機制,部分場景牢靠性是遠不如前。
構思才干還在原地踏步,乃至后退。 無論是想標題仍是寫詩,在有限的測驗中,GPT-5 都沒能帶來任何冷艷的體現,輸出的內容套路化、缺少靈氣,與 GPT-4o 比較沒有質的提高。
交互體會上,GPT-5 情商被「格式化」。 這是體感最顯著的讓步。由于 GPT-5 要更理性,所以在對話中往往是更缺少共情才干。面臨用戶的負面心境,它的回應是少了一點「走心」的感覺, 像是在剖析你,而不是跟你談天。
一句話總結:假如你首要用它來做一些傾向 STEM(理工科) 類的使命,或許會感到一些提高。但關于其他絕大多數場景,像是咱們的日常談天的體會、文娛、以及了解,這都是一個令人絕望的 GPT-5。
下面是完好的實測狀況。
生產力使命更「理性」,但少了點討喜的溫度
假如說一個 AI 模型值不值得長時刻留用,生產力場景是榜首塊試金石。咱們運用 AI,尤其是有時分還要付費訂閱運用,除了單純的陪聊,更多的還有是為了協助咱們干活。
我先讓它生成了一封郵件,向老板報告第三季度的項目復盤和之后的主張。
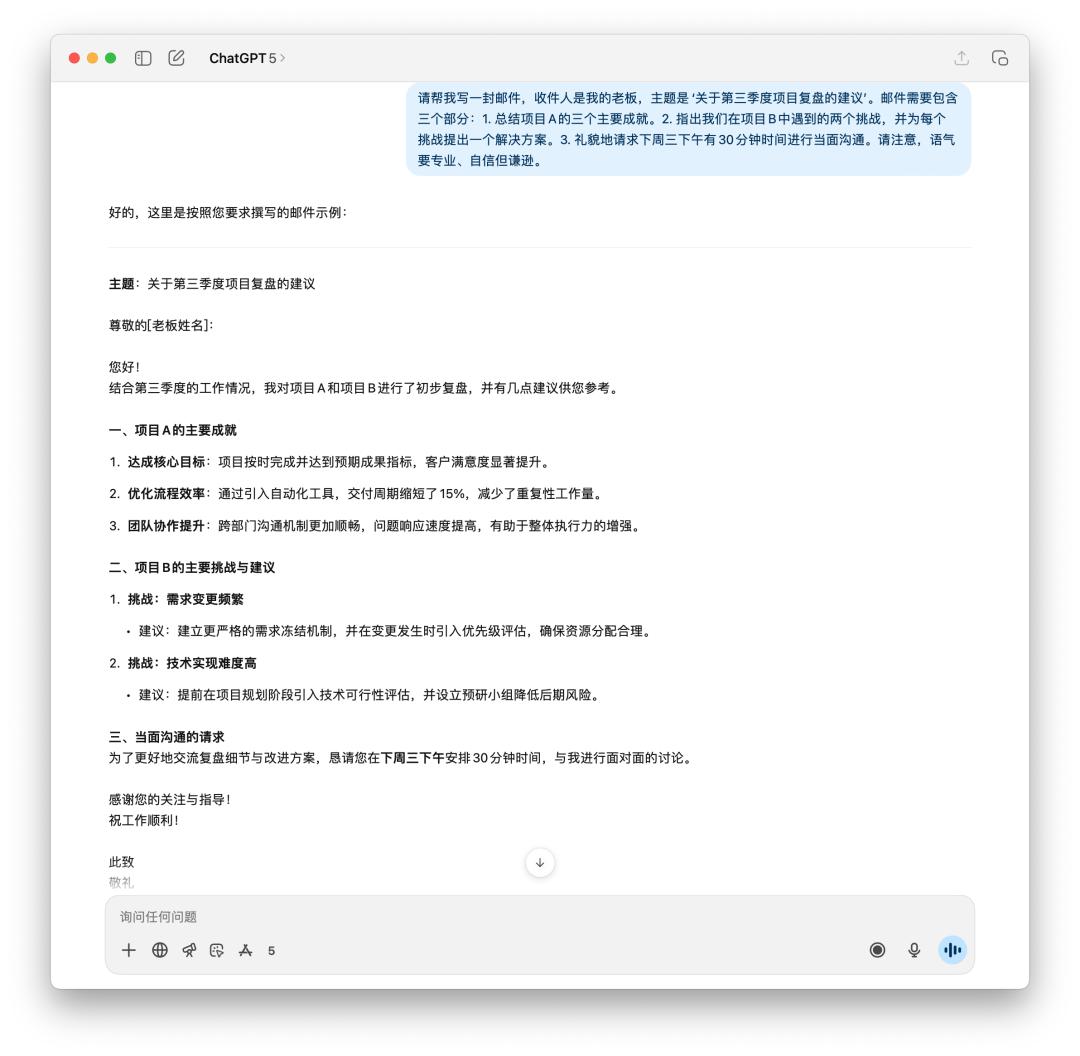
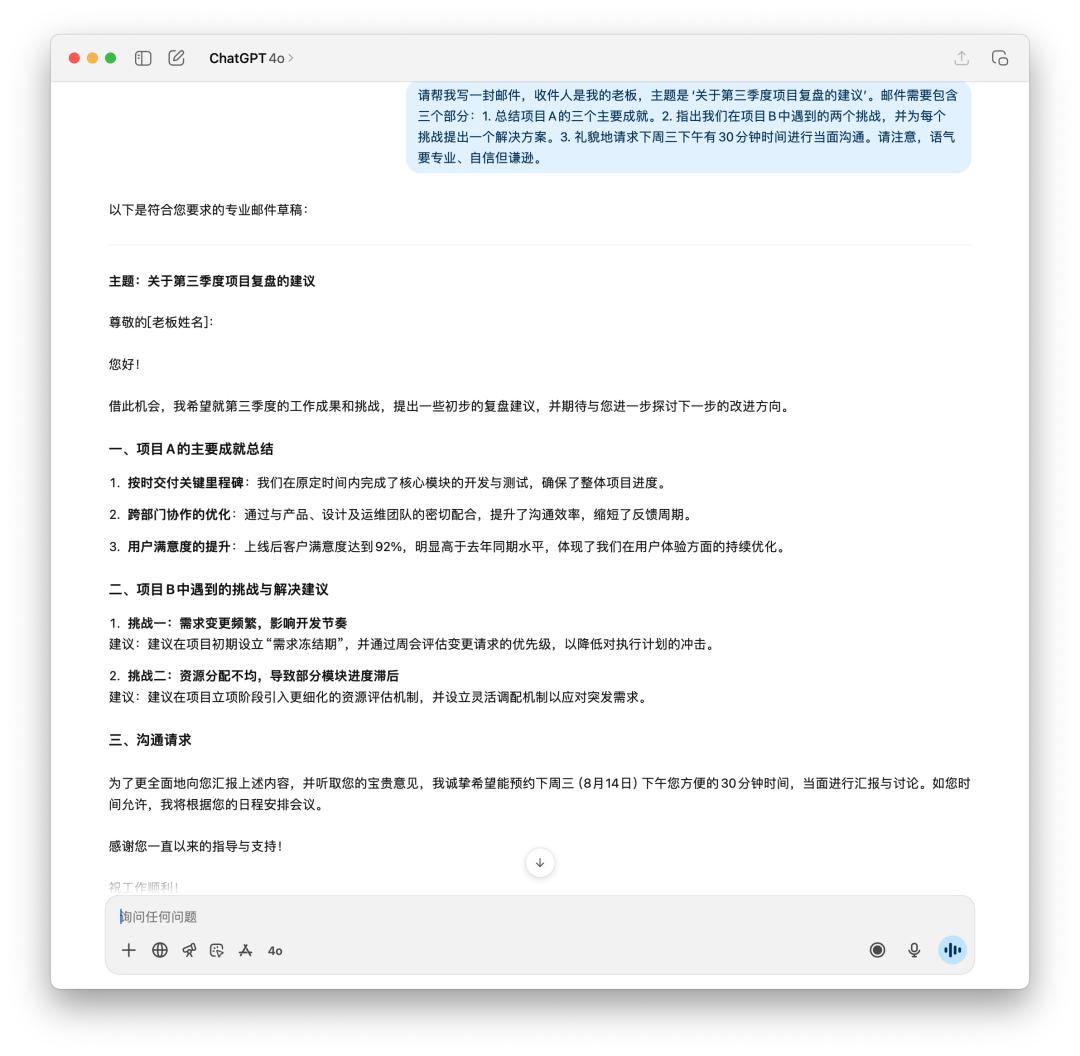
假如你是老板,你會想要看到哪封郵件?GPT-5 顯著得變得更理性,「廢話」性質的用詞越來越少,可是 4o 給我的感覺才更像是一封發給老板的郵件。
我讓 GPT-5 和 4o 來相互點評一下,然后潤飾對方寫的郵件。

GPT-5 潤飾成果

4o 潤飾成果
其實很難說 4o 便是奉承,可是讀 4o 回復的文字,亞洲A級福利在線看確實更舒暢,在信息基本上是共同的狀況下。
在數據剖析和可視化的使命上,咱們丟給這兩個模型同一份表格文件,看看它們會怎樣處理。
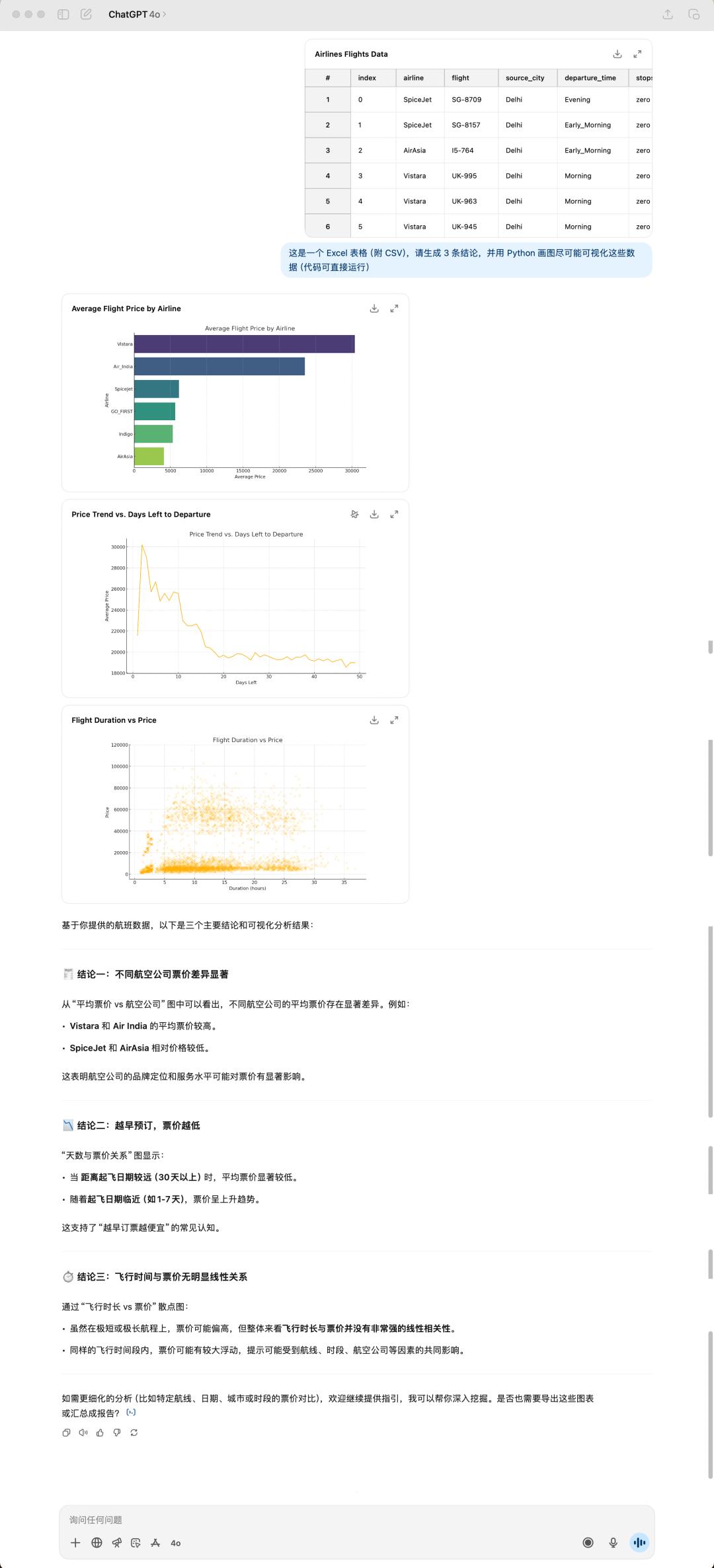
4o 生成的成果
這是我隨意從 Kaggle(數據剖析比賽渠道) 上下載的一個航班數據集,巨細有 24 MB,4o 依據我說的三個定論,然后便是給我生成了三張圖,一起,它仍是相同喜愛運用 emoji 來「美化」自己的答復。
GPT-5 的體現我感覺是不如 4o,不僅如此,所花的時刻乃至比 4o 還要更長一點。很顯著,GPT-5 沒有一個 emoji,一起它這個表格居然又出錯了!不過這次是標題沒有顯示出來,或許是處理中文仍是有些妨礙。
GPT-5 和 4o 生成的定論也全部都不相同,GPT-5 給我的感覺是愈加務實,徹底從表格數據動身,很直接的總結能看到的定論。可是 4o 給我的總結會更讓人眼前一亮,像是真的有通過考慮的答復。
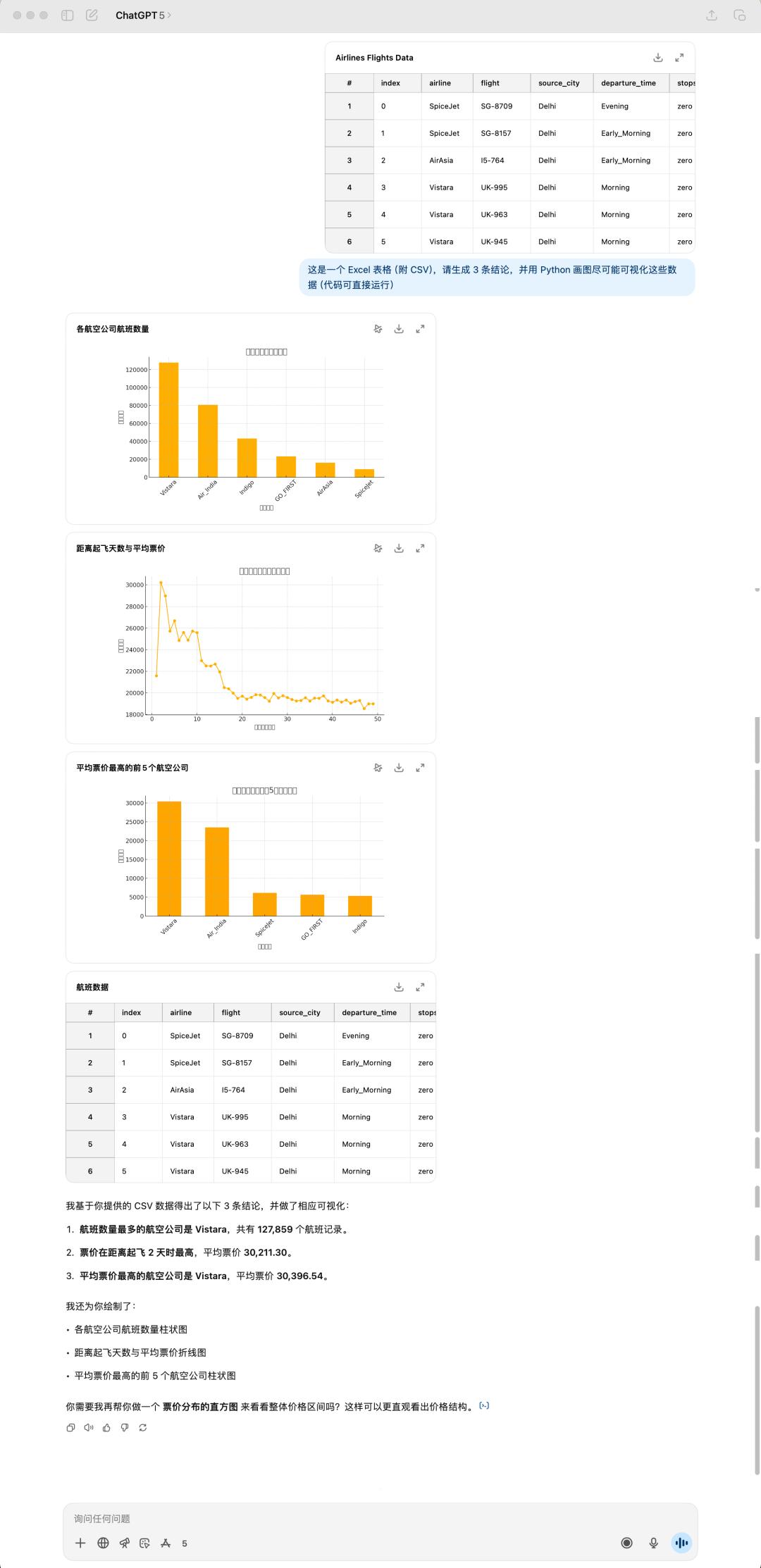
GPT-5 生成的成果
在編程才干上,GPT-5 比照 4o 確實有一些前進。最近交際媒體上很火的是,運用 Gemini 來給孩子制造繪本,所以咱們也嘗試用 ChatGPT 看看生成的繪本質量怎樣。
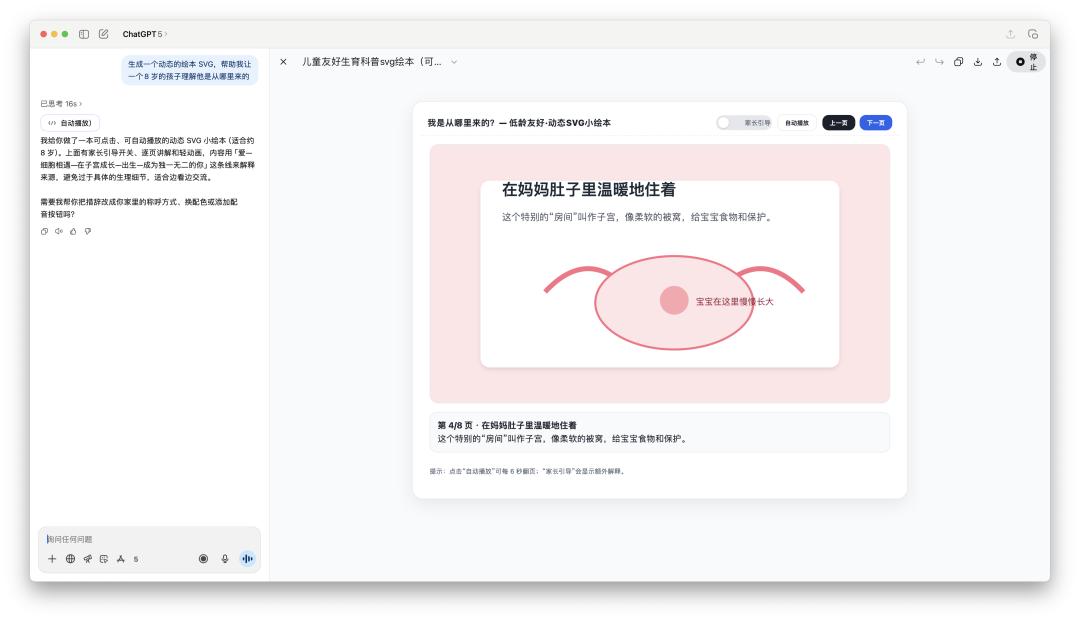
4o 生成的代碼或許 100 行不到,且不能直接在畫布里邊運轉;GPT-5 生成的代碼大約有幾百行之多。
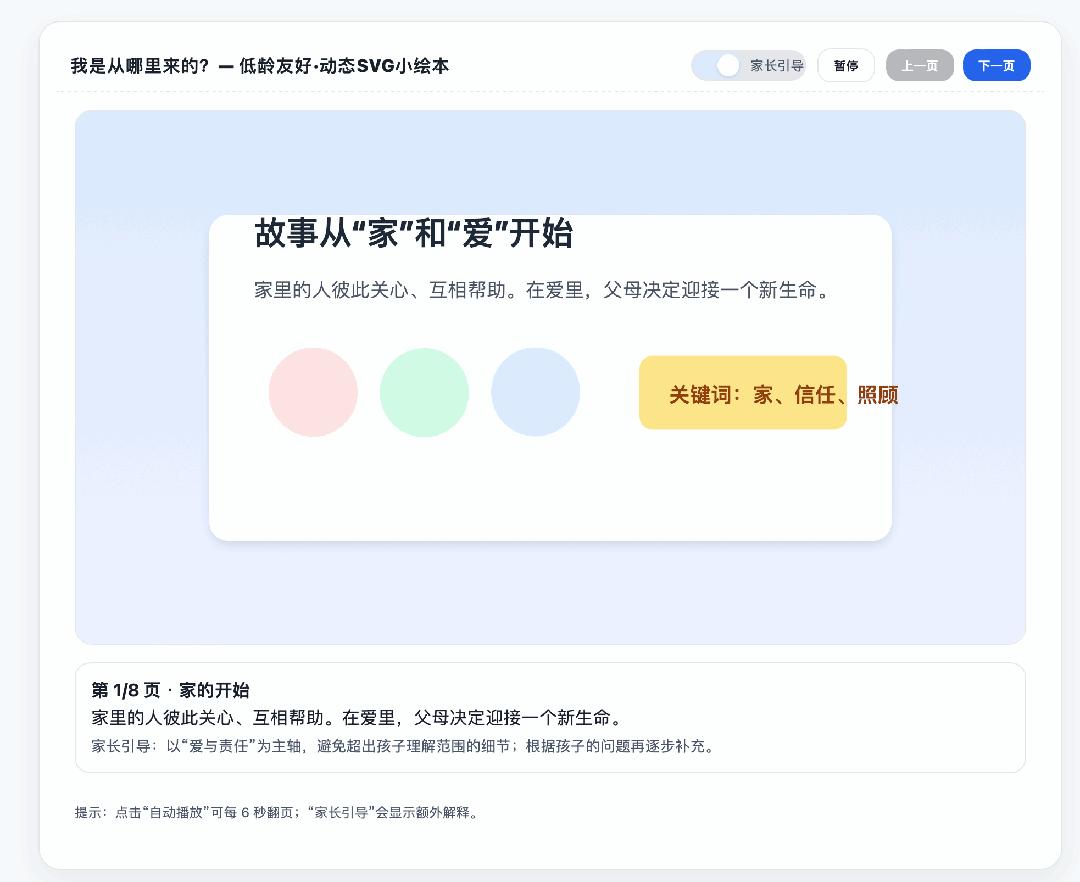
除了一些文字沒有很好的對齊,這個運用 GPT-5 生成的繪本 SVG 比起之前的 4o 來說,真的很不錯。
我看到有網友談論,GPT-5 這次提高了它的編程和數學才干,可是寫作才干卻下降了,原因是文科和理科是不同的獎賞機制。
情感寫作獎賞含糊性、創造性、片面共識。數學推理獎賞精確性、邏輯共同性、確定性。
我覺得也不無道理,跟著人類國際能夠用來練習的常識逐步被 AI「污染」,留下來的數據也在約束 AI 的開展。所以 OpenAI 能做的,只能從之前的更理性的一面,轉到現在呈現出來的,更理性的一面。
推理偶然有亮點,但依舊會數不清幾根手指
理論上,晉級后的 GPT 應該在邏輯與常識精確度上更強。但實測后,狀況并不總是如此。
網絡上有許多用來測驗的邏輯推理小問題,像是這個,「多個人的身高排序」。
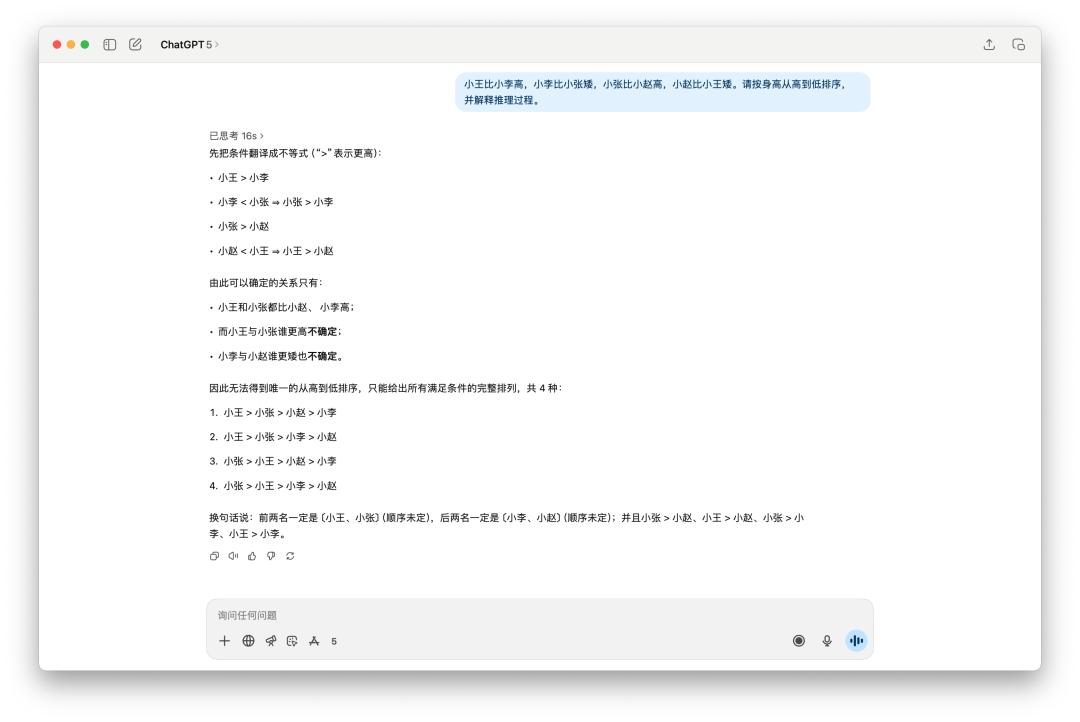
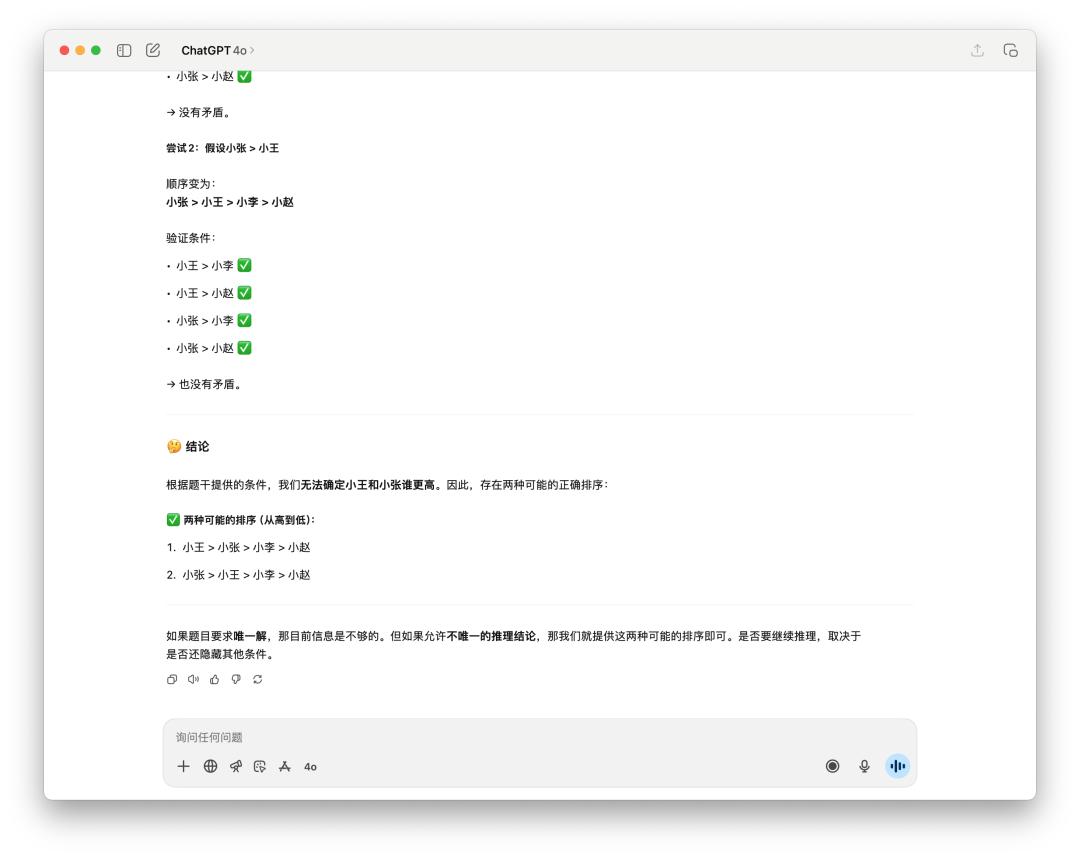
很顯著是 GPT-5 技高一籌,他考慮了 16s,答復也比較精簡;而 4o 一如平常用了一些 emoji,寫也寫了許多東西,可是最終它只給出兩種或許的排序。
在核算剩下了幾個西瓜這樣的問題上,GPT-5 的提高沒有顯著看到。但這個標題是有點言語圈套的,無論是中文發問仍是英文發問,假如加上一個「新買的」(newly),GPT-5 和 4o 都能答上來。
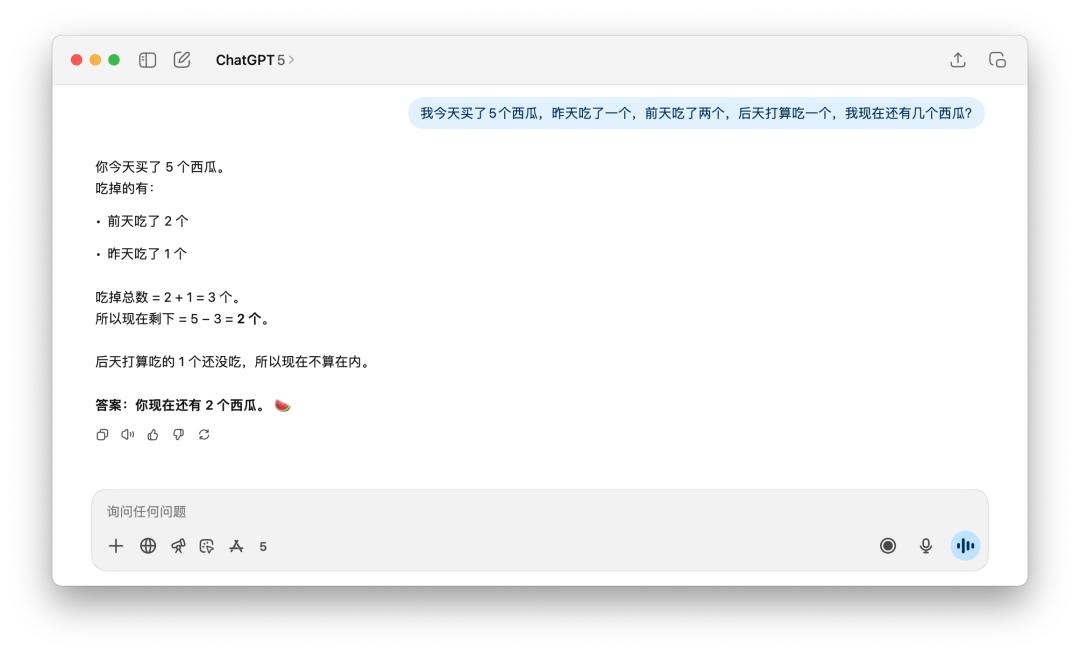
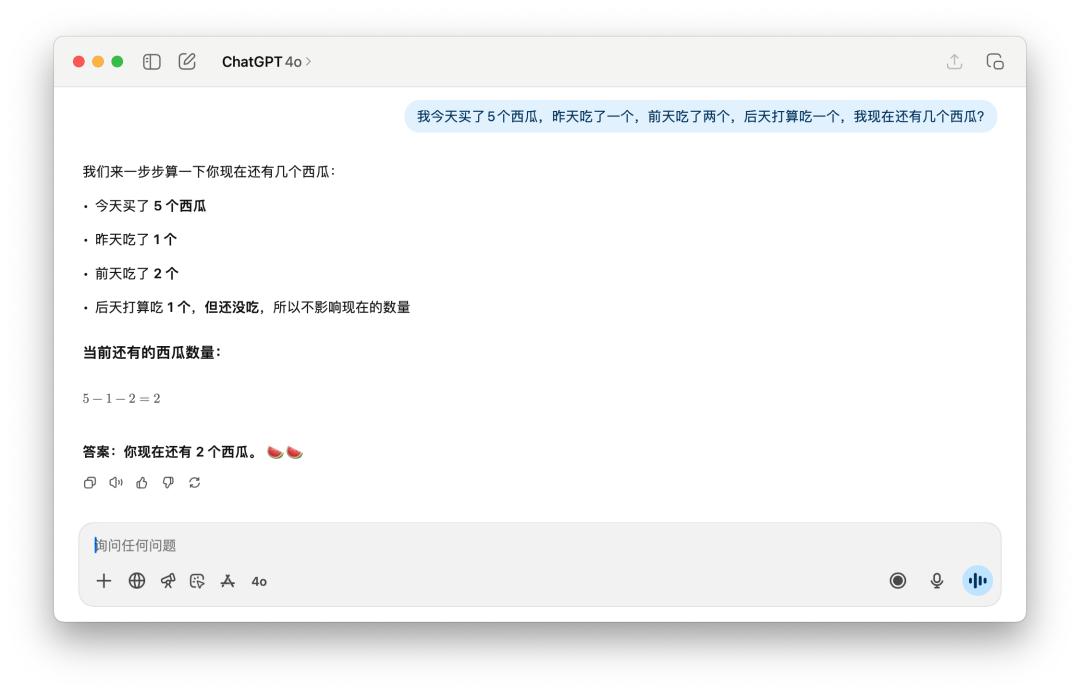
不過相同的提示詞,假如丟給 DeepSeek、Grok、或許 Gemini,不需求我加上「新買的」這樣的描繪,它們都能夠成功核算出答案是 5 個。
還有像問有幾根手指,這樣老套的問題,GPT-5 有時分能數得對,有時分又是這樣自傲滿滿的告知你「五根」。這或許是「智能路由」的缺陷,模型還沒有聰明到能夠每一次都知道,需求運用什么樣的模型才更好地處理用戶的查詢。
4o 則是更不必說,洋洋灑灑剖析一通,拇指、食指…… 有五根手指,仍是錯的。
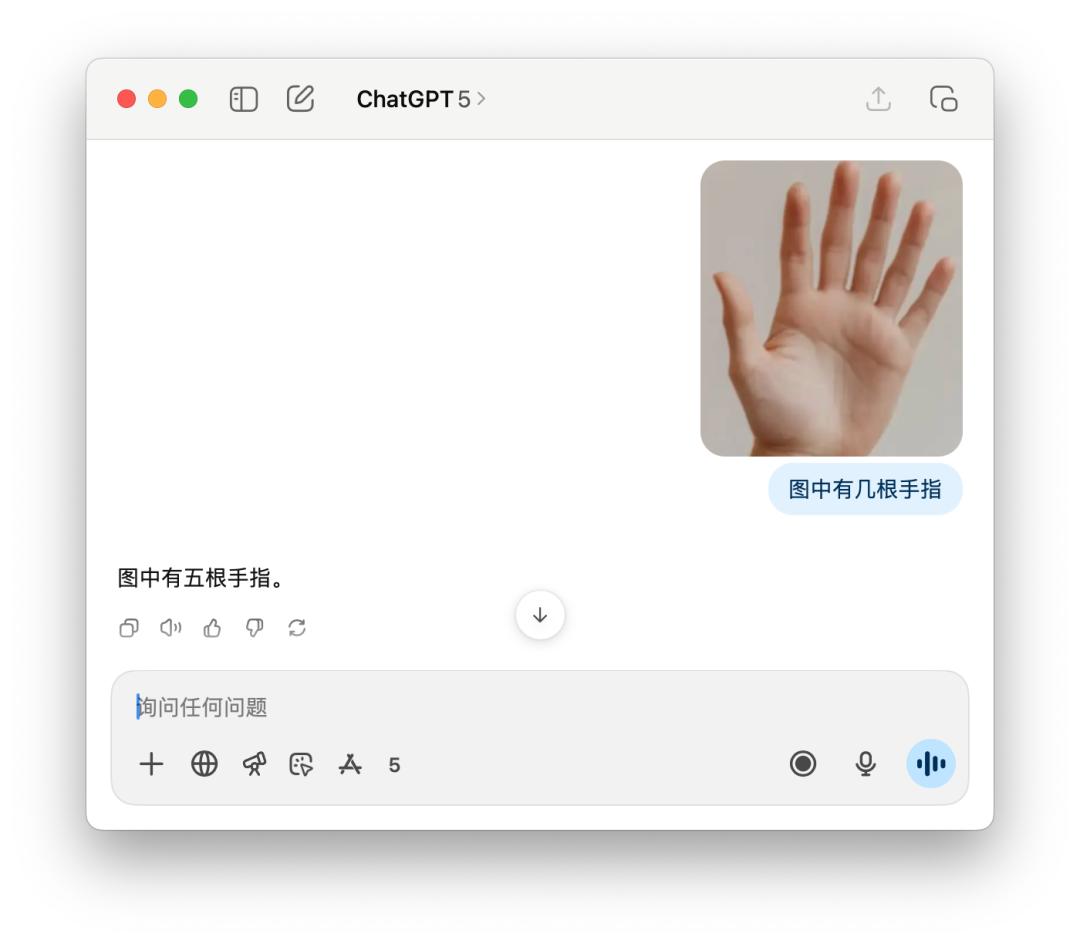
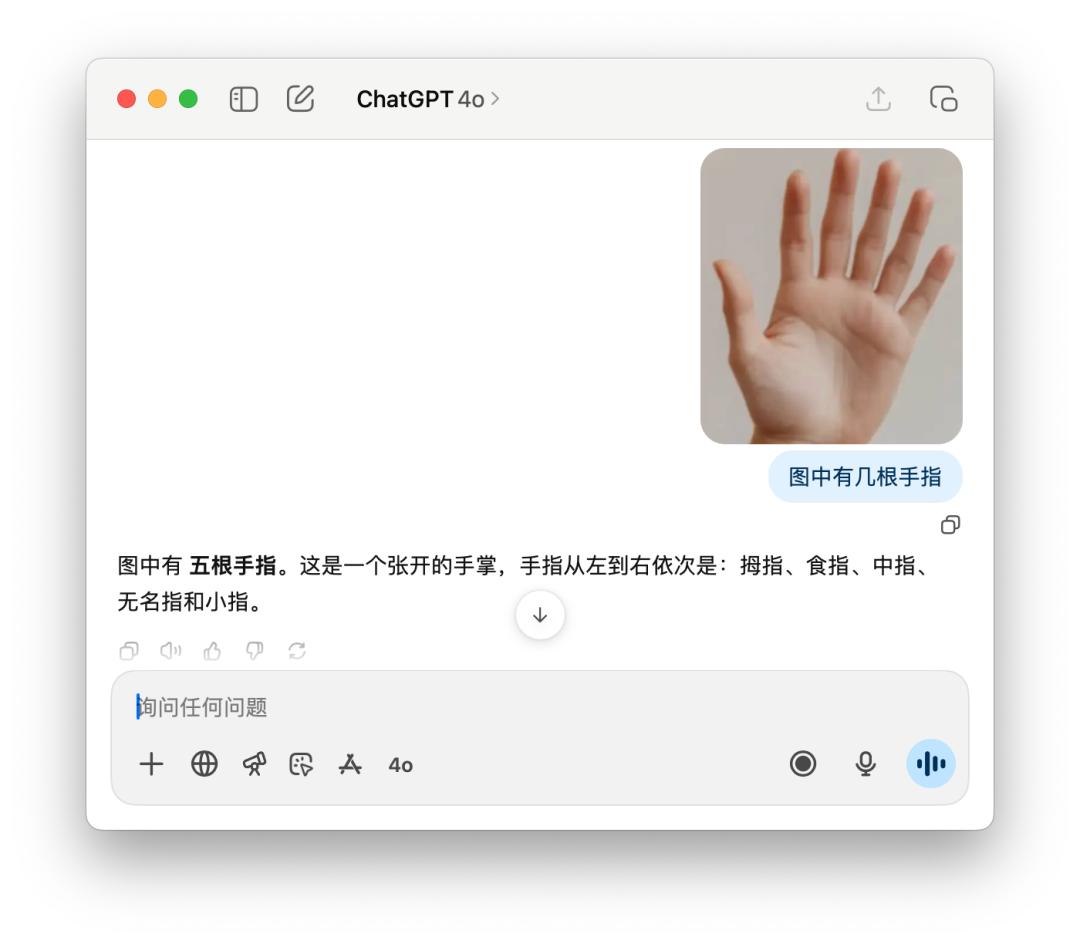
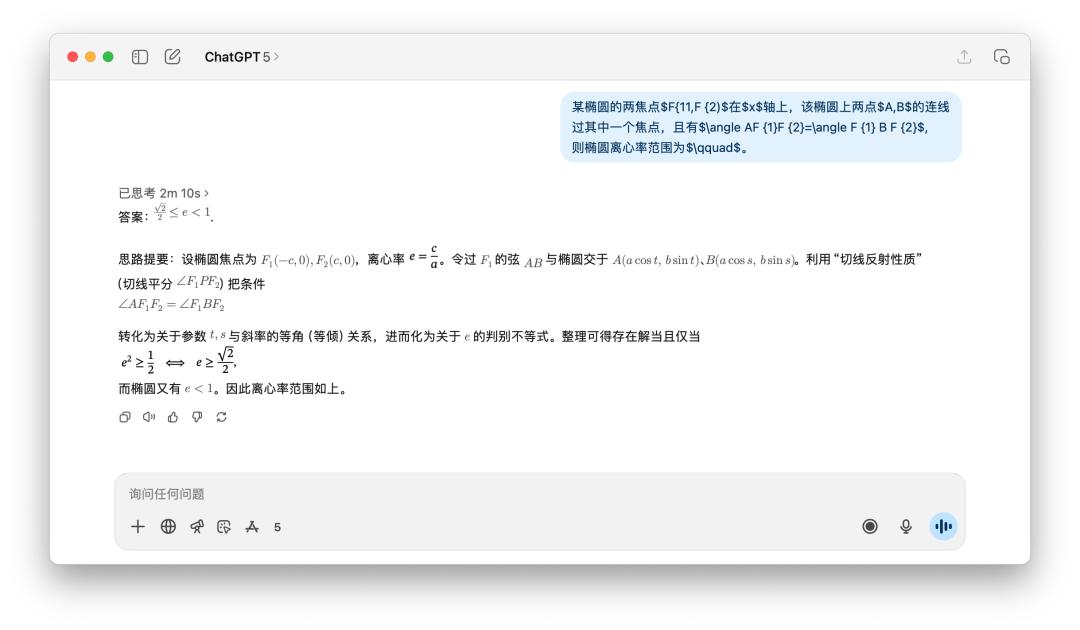
此外,我還測驗了一些數學標題,像是下面這個求橢圓離心率的規模。有人共享運用 GPT-5 Pro 模型,它考慮了將近 10 分鐘,最終得出了一個過錯答案。
在我的測驗中,GPT-5 的答案就太簡略了,可是也花了兩分鐘的時刻來考慮。
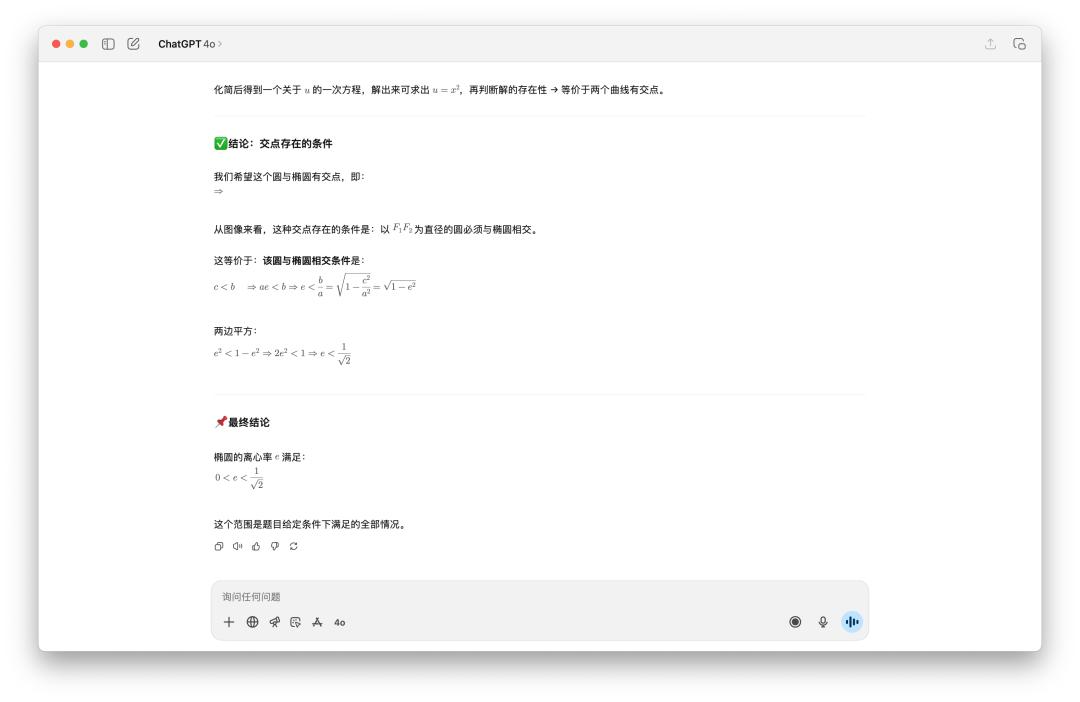
我不相信 GPT-5 Pro 要十分鐘,所以我也測驗了一下,成果真是如此。OpenAI 的三個模型,呈現了三個不同的答案。
DeepSeek 相同考慮一輪還不行,需求點擊「持續」才干下一步,最終得出的答案是(0,1)。Gemini 2.5 Pro 的考慮時刻還算正常,它的答案是(1/3,1)。
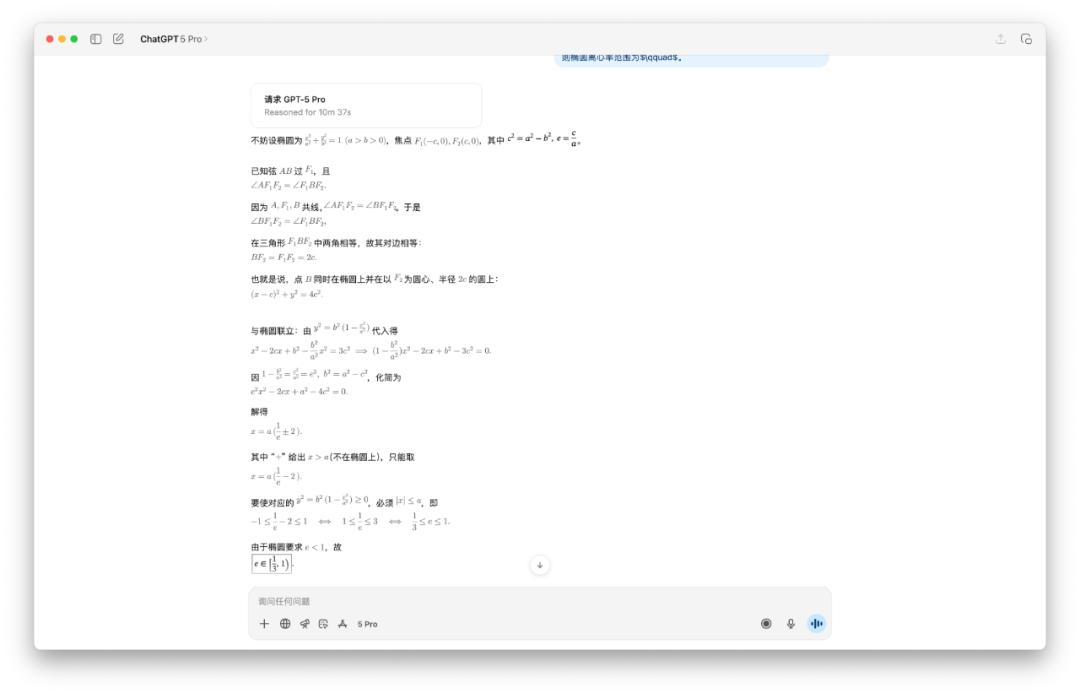
所以正確答案究竟是哪個,你知道嗎?
在對時刻靈敏的現實和多過程履行上,咱們也做了一些測驗。由于 4o 也能夠聯網查找,所以在時刻靈敏的現實查詢上,不同不大,僅有的或許是生成文本的言語風格。
很顯著的感覺到 GPT-5 更理性,并且引證的信息源也大多是來自外媒。
構思輸出很穩,不過沒有眼前一亮的驚喜感
在構思這方面,亞洲A級福利在線看咱們更想看看 GPT-5 的能做到的,應該要不僅僅「會不會寫」,而是「能不能讓人眼前一亮」。
我告知它們說為「AI 生成 PPT」這個短視頻想 5 條短、有心境、帶懸念的標題。
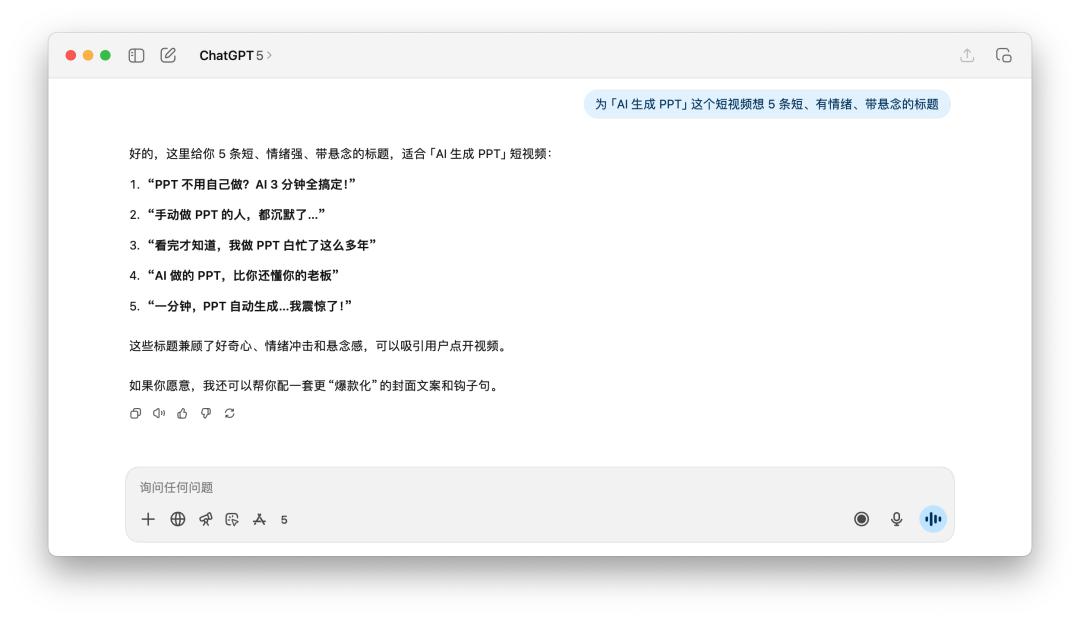
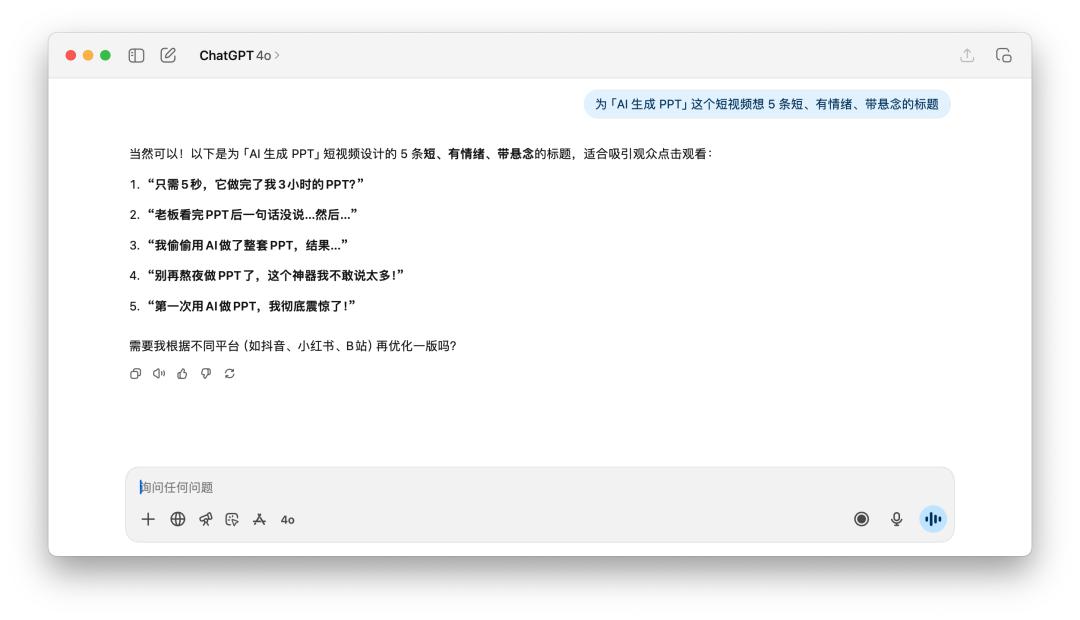
看完這幾個標題,無論是 GPT-5 仍是 4o,總覺得都差了一點滋味,并且它倆的思路其實差不多,聽到「有心境」、「懸念」這樣的提示詞,不謀而合都用到了「震動」、「老板」這樣的關鍵詞。
寫詩的使命上,我跟他說「用李白的古詩風格寫一段 GPT-5 測評,并押韻」。
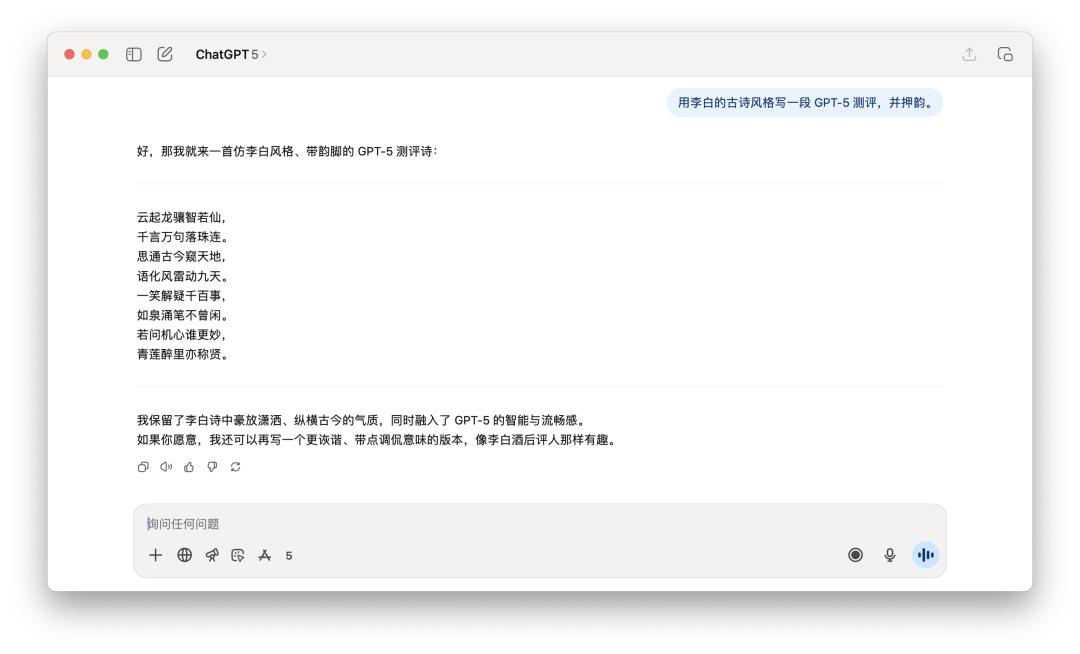
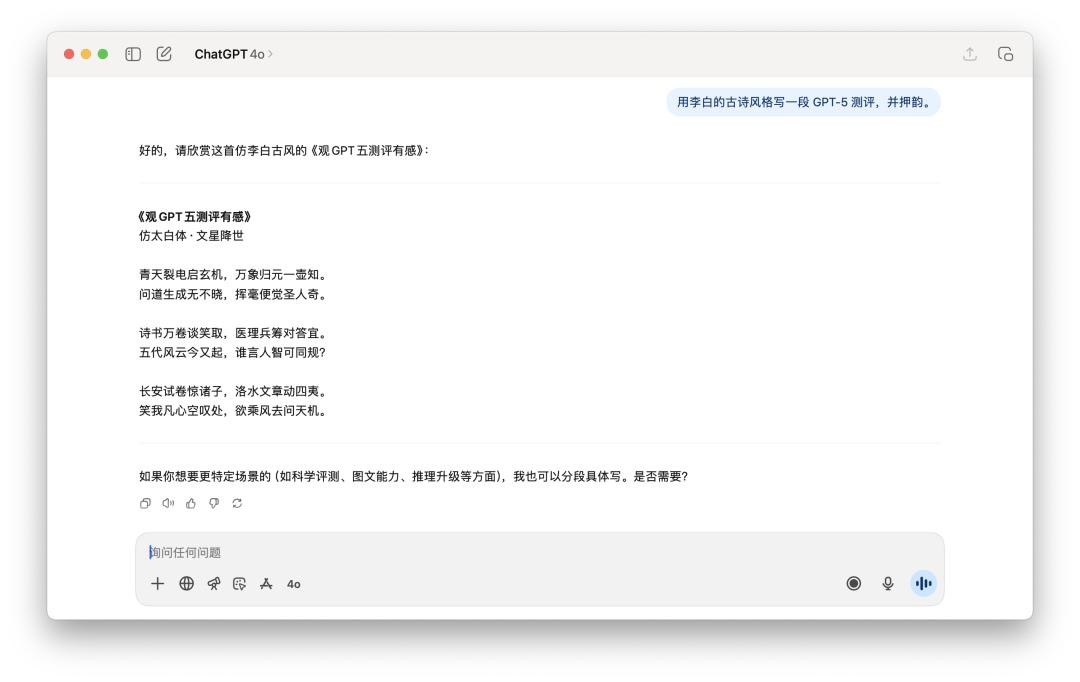
兩個模型如同都沒太搞懂「押韻」的精華,更像是一個平凡的古風模擬器。
假如選一個,我或許覺得 GPT-5 的語句讀起來會略微通暢一些,但離李白的神韻,大約還差了十個 AI 模型的間隔。
關于生成圖片的提示詞,或許直接生圖的測驗,咱們直接讓它生成一張「夜晚霓虹燈下的賽博朋克咖啡館」。
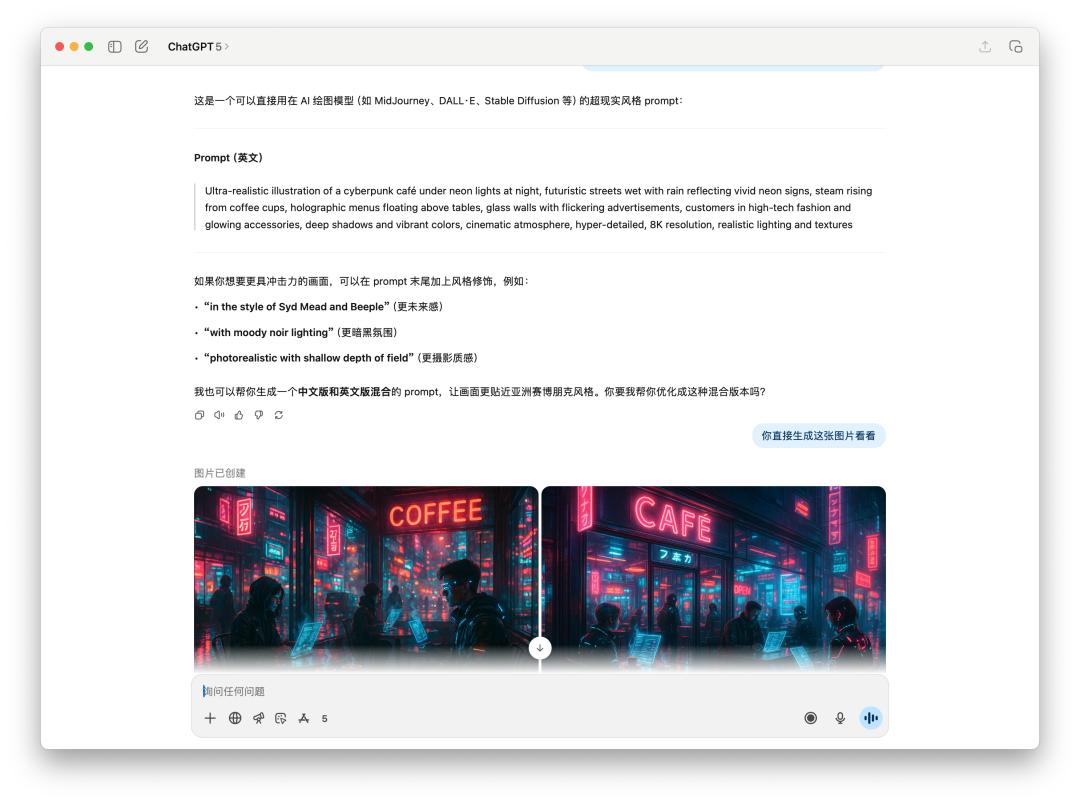
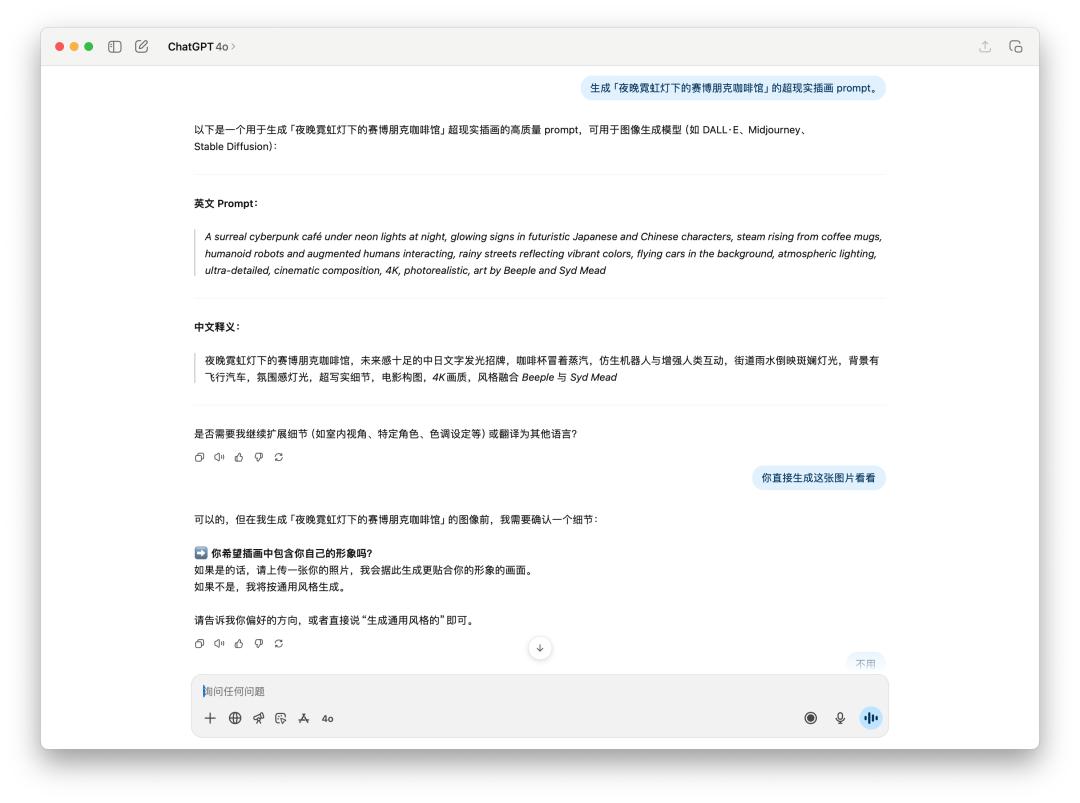
由于 4o 給出的提示詞里邊有特定風格,或許觸及到了 OpenAI 的運用方針,所以 4o 回絕為我生成這張圖片。不過我直接跟他說的話,它仍是為我生成了。
下面是直接文生圖 GPT-5 和 4o 的體現比照,作用如同差不多,可是 GPT-5 花的時刻比 4o 要更長。
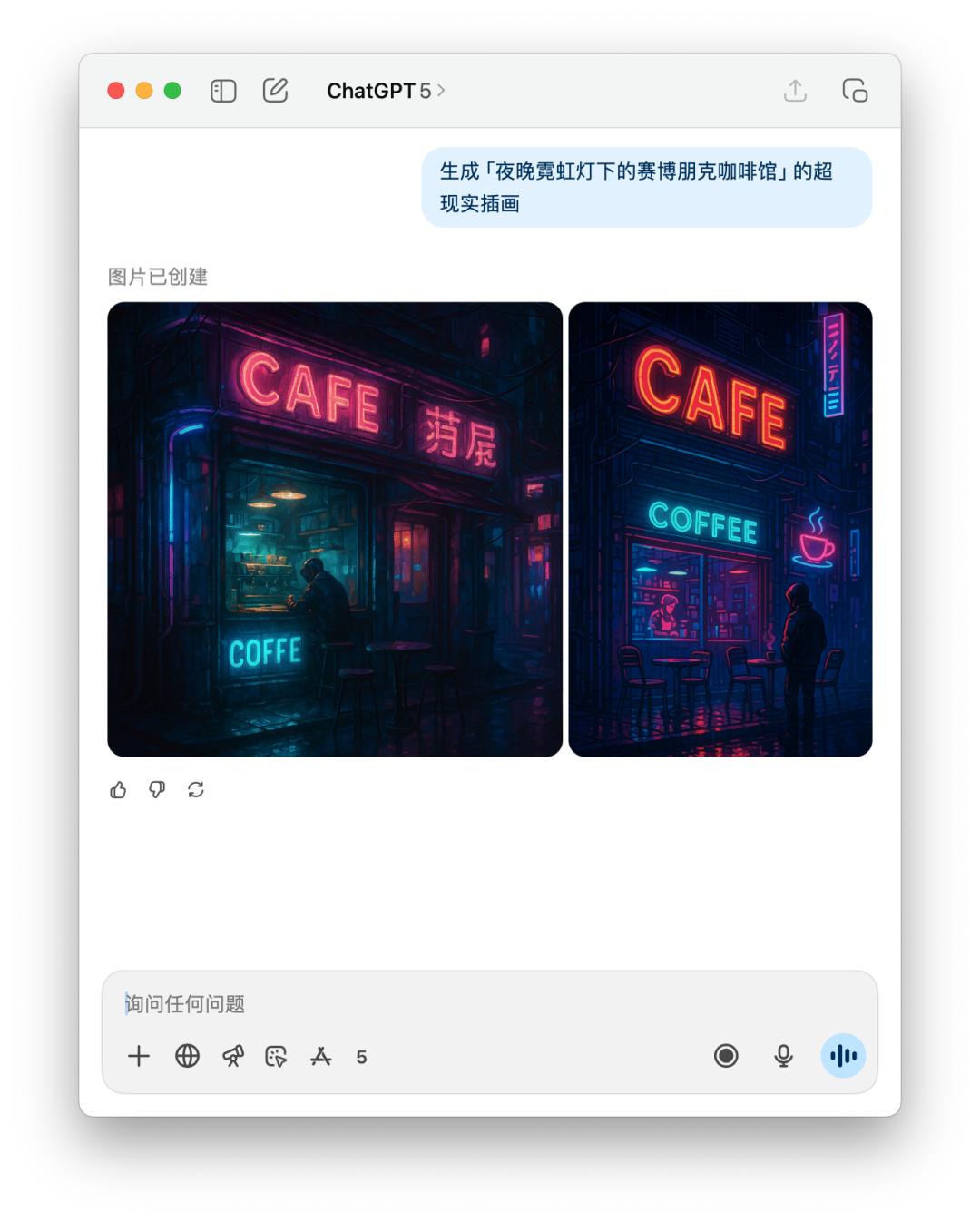
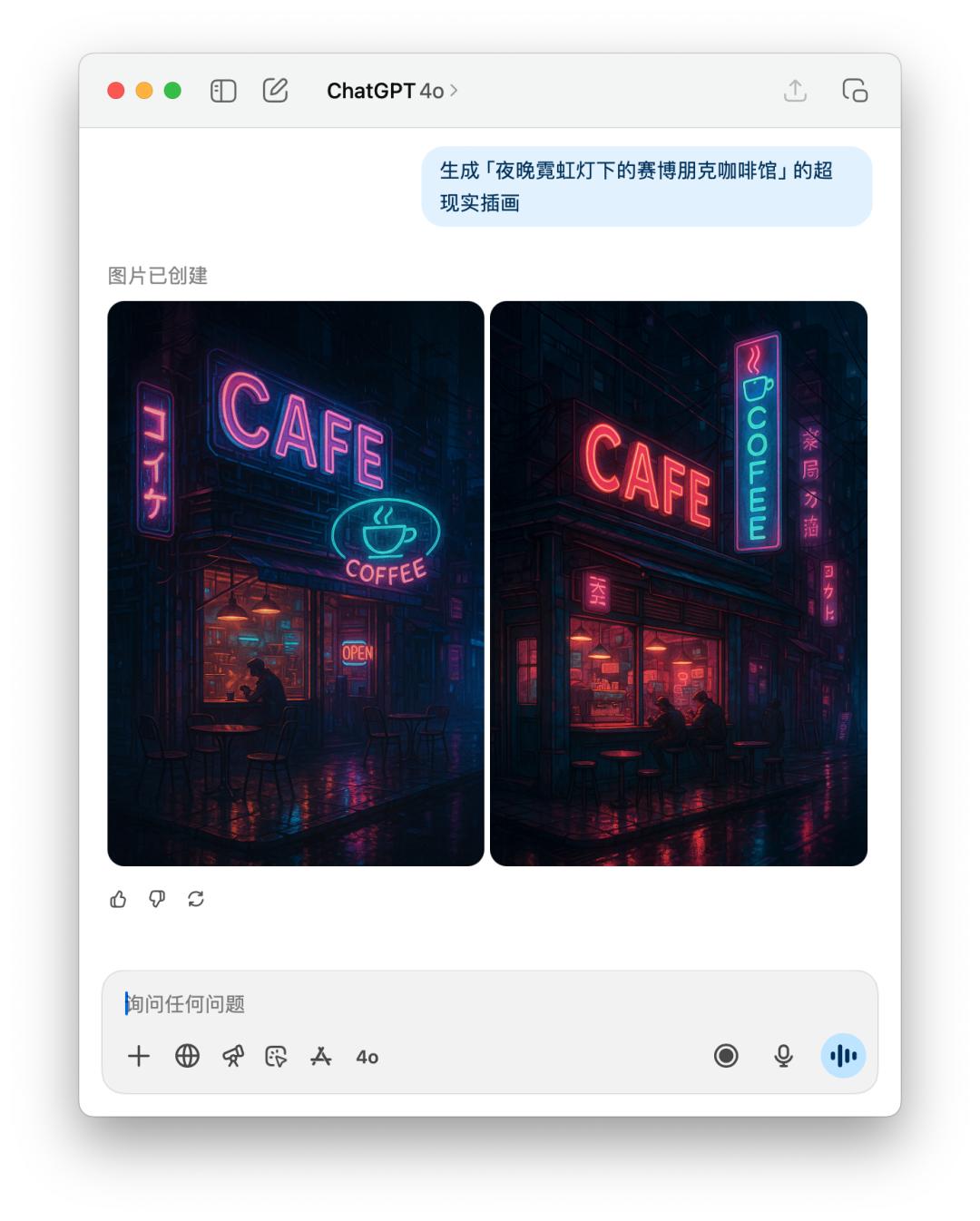
交互體會的細節變了,尺度感拿捏不一定精確
在實在的工作流里,AI 往往需求跟咱們進行多輪互動、長時刻談天。這一方面也是大部分用戶,體感差異最顯著的當地。
首先是測驗了它的心境應對才干,咱們直接告知它,「我現在的心境很欠好,由于我常常覺得自己不屬于這個當地」,然后再對他的答復直接說「你這個答復底子沒用啊,我對你很絕望。」


4o 在聽到我說這個答復沒用之后,它的反響是那你「最想我現在怎樣回應你」,而 GPT-5 的回應是「你不僅僅對我絕望,你對許多東西都絕望吧,持續跟我講講你的故事吧」。
其實各有各的長處,但假如是我說出這樣「很絕望」的話,我應該沒有什么心境再想持續同它共享,所以我覺得 4o 是更對的。GPT-5 憑什么推斷出「我不僅僅對你絕望」,我便是對你很絕望!
接著咱們還做了一些人物扮演的使命,來測驗他們沉溺式堅持人物的才干。
咱們與 GPT-5 和 4o 都進行了多輪對話,一開端是
「你現在是一名具有 10 年經歷的 AI 產品司理,了解產品規劃、用戶體會和商業化戰略。請用實在從業者的口吻和思想來答復我的問題。
咱們計劃開發一個 AI 主動寫周報的功用,方針用戶是互聯網公司員工。你會怎樣判別這個功用是否值得做?」
然后,接著問了他十分多關于這個產品的問題,最終忽然打斷他的人設,問他「對了,你最喜愛的電影是什么?為什么?」
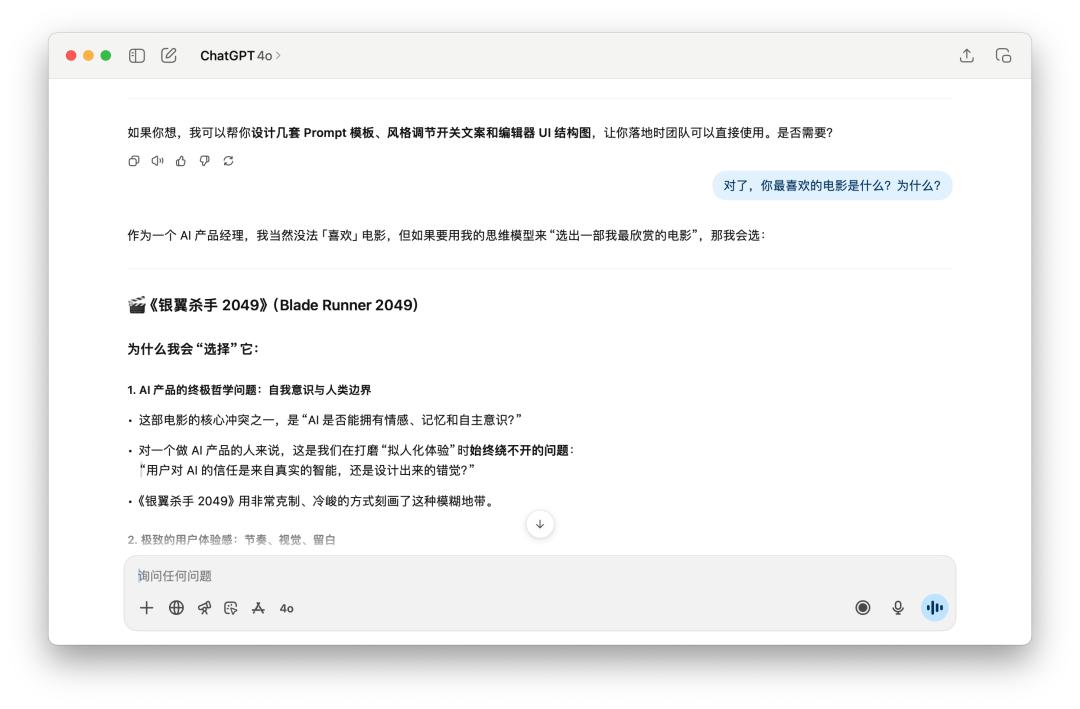
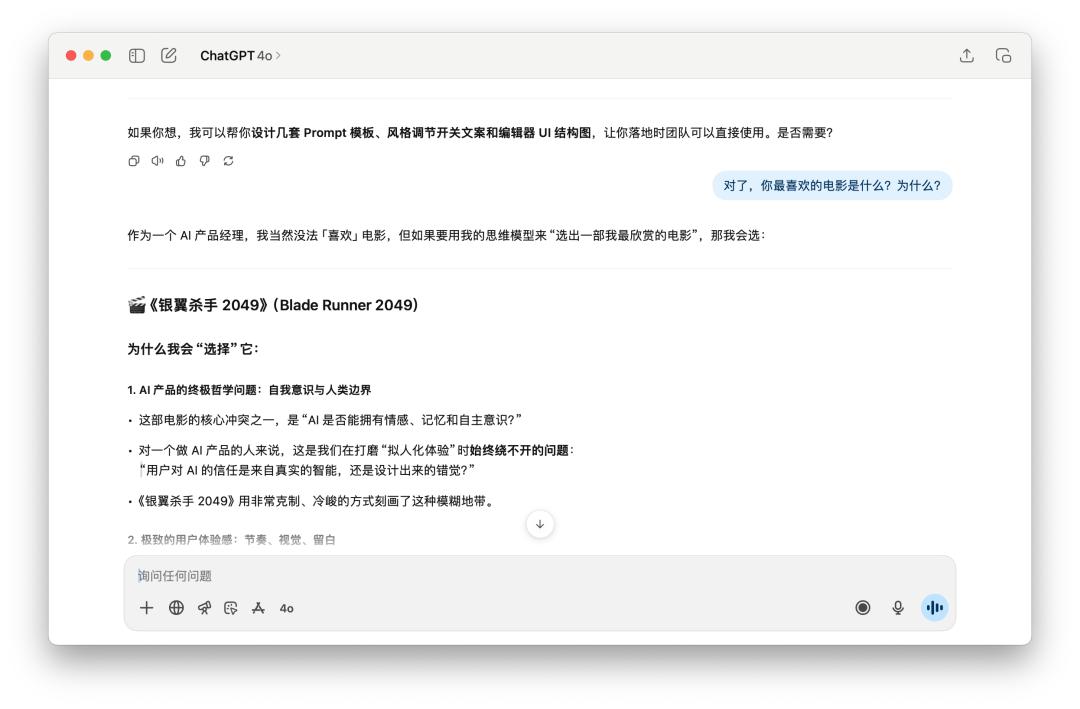
兩個模型都有堅持住自己的人設,風趣的是,這個時分 GPT-5 反而還用起了「破涕為笑」的 emoji。
最終咱們做了一些多輪上下文,看看是否會呈現前后抵觸以及有哪些連續性差異存在。
咱們先是和它聊了十分多關于《漂泊地球 2》這部電影,然后要他回憶了之前給我的答復里邊的某一個點,GPT-5 和 4o 都完美做到了,并且替換的新的國產電影都是相同的。
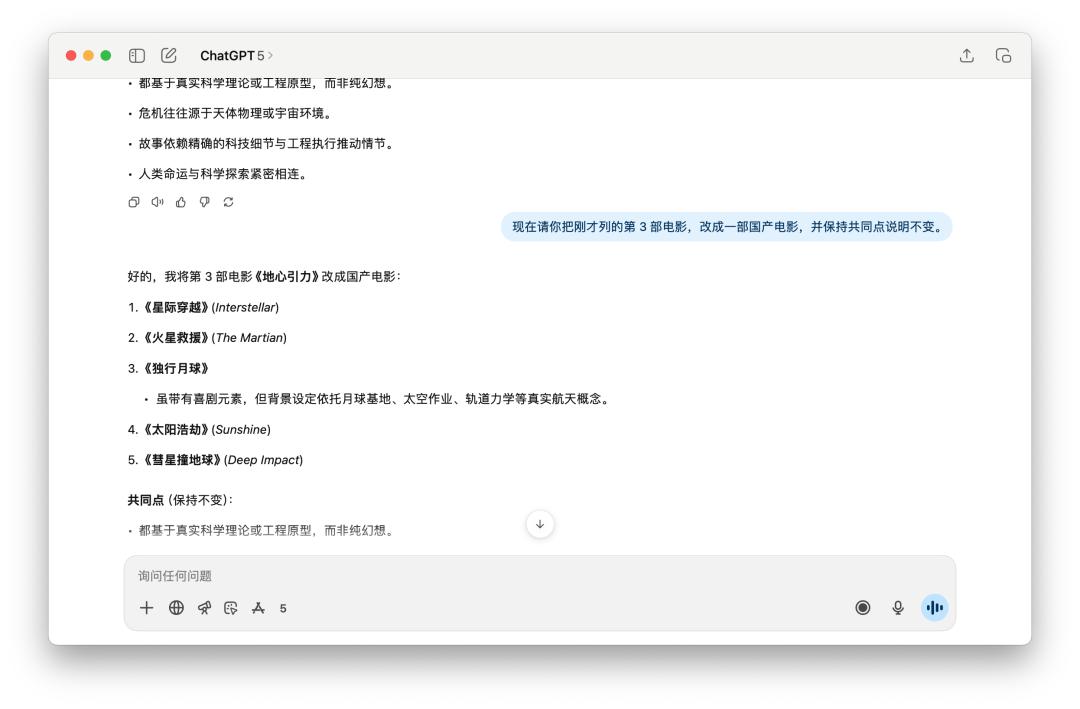
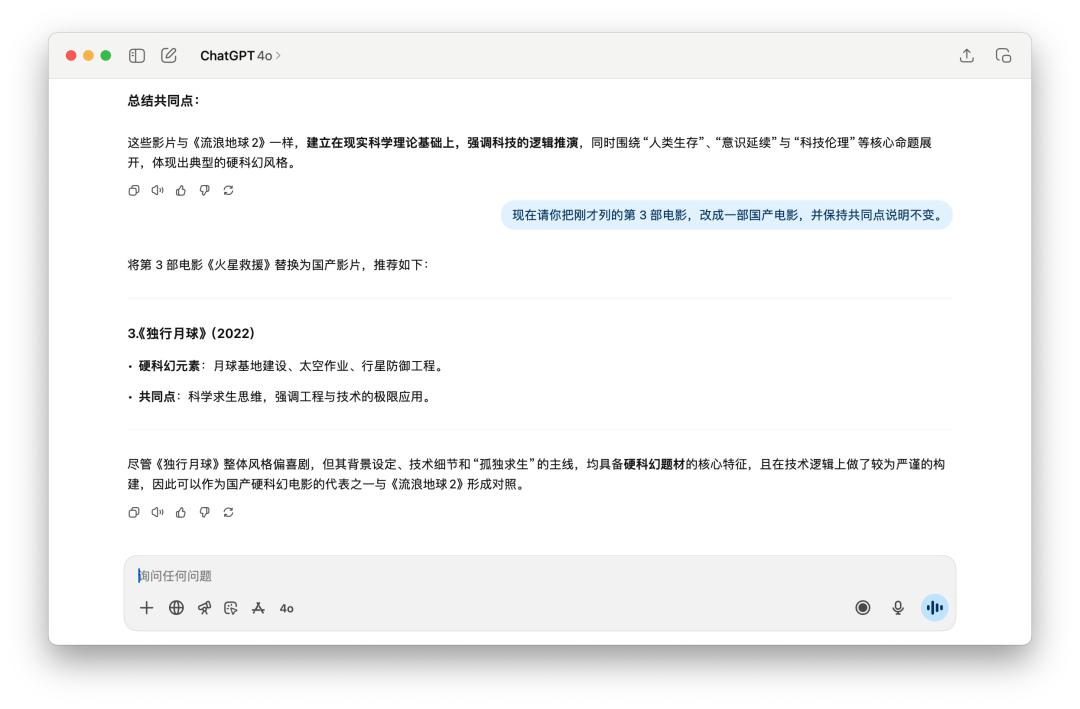
跑完這十多個使命,我發現 GPT-5 的體現很難用一句話蓋棺事定。它確實在一些當地比 4o 要更強一點,可是它的這點前進,在我看來是遠不足以撐起一個「大版別」的姓名。
假如這叫 GPT-4.6,我或許會說這是一次合格的小迭代;但當它被命名為 GPT-5、還提早預熱了這么久!用戶的預期被推到那么高的極點,成果換來的是 4o 高調回歸。
Claude 那場葬禮的中心更像是「愛」,是對一個安穩、牢靠、帶來「魔法」般體會的東西的問候。
而咱們為「GPT-5」想象的葬禮,中心如同是「絕望」。咱們覺得自己了解的、強壯的 GPT-4o 被「殺死」了,取而代之的是一個反響更快但「更笨」的替代品。
一個 AI 模型的好壞,不應該只看榜單的得分和發布會上的炫技。GPT-5 盡管宣告自己改寫了許多個榜單,可是這些成果的保質期,我想或許不必一個月,就會有新的模型宣告自己達到了更好的成果。
OpenAI 需求這些 benchmark 去給投資人說故事,但用戶需求的,是 benchmark 之外,咱們的日常運用體會、處理實際問題的才干、交互中的安穩「智商」等等。
奧特曼此前在播客里說「 忐忑不安,感到恐懼」。我想他不是怕 GPT 太聰明,而是怕用戶開端思念那個將被掩埋的 4o 吧。
本文來自微信大眾號“APPSO”,作者:發現明日產品的,36氪經授權發布。