面臨對立進犯,具身智能體除了被迫防備,也能自動出擊!
在人類視覺體系啟發下,清華朱軍團隊在TPMAI 2025中提出了強化學習驅動的自動防護結構REIN-EAD。
該結構讓智能體也能學會“看第二眼”,進步對立場景下的感知魯棒性。

對立進犯已成為視覺感知體系安全性和可靠性的嚴峻要挾,這類進犯經過在三維物理場景中放置精心規劃的擾動物體(如對立補丁和三維對立物體)來操作深度神經網絡的猜測成果。
在人臉辨認和自動駕駛等安全要害范疇,此類縫隙的成果尤為嚴峻,過錯猜測或許嚴峻危害體系安全性。
但是,現有防護辦法多依靠進犯先驗,經過對立練習或輸入凈化等手法完成對有害畫面的“被迫防衛”,疏忽了與環境交互可取得的豐厚信息,遇上不知道或自適應進犯時作用敏捷衰減。
比較之下,人類視覺體系更為靈敏,能夠經過自動探究與糾錯,自然地下降瞬時感知的不確定性。
相似的,REIN-EAD的中心在于運用環境交互與戰略探究,對方針進行接連調查和循環猜測,在優化即時準確率的一起統籌長時刻猜測熵,緩解對立進犯帶來的錯覺。
特別地,該結構引進了依據不確定性的獎賞塑形機制,無需依靠可微分環境,即可完成高效戰略更新,支撐物理環境下的魯棒練習。
試驗驗證標明,REIN-EAD在多個使命中明顯下降了進犯成功率,一起堅持了模型規范精度,在面臨不知道進犯與自適應進犯時相同表現出色,展示出強壯的泛化才能。
首要奉獻
(1)提出REIN-EAD模型,交融感知與戰略模塊來模仿運動視覺機制
論文規劃了一種結合感知模塊與戰略模塊的自動防護結構REIN-EAD,學習人類大腦支撐運動視覺的工作辦法,使模型能夠在動態環境中繼續調查、探究并重構其對場景的了解。
REIN-EAD經過整合當時與前史觀測,構建具有時刻一致性的魯棒環境表征,然后進步體系對潛在要挾的辨認與適應才能。
(2)引進依據累計信息探究的強化學習辦法以優化自動戰略
為進步REIN-EAD的戰略學習才能,論文提出一種依據累計信息探究的強化學習算法,經過引導式密布獎賞優化多步探究途徑,引進不確定性感知機制以驅動信息性探究。
該辦法強化了時刻上的一致性探究行為,并經過強化學習范式消除了對可微環境建模的依靠,使體系能夠自動辨認潛在高風險區域并動態調整行為戰略,明顯進步了觀測數據的有用性與體系安全性。
(3)提出離線對立補丁近似技能(OAPA),完成功率高、泛化強的防護才能
針對3D環境下對立練習核算開支巨大的應戰,論文提出OAPA技能,經過對立補丁流形的離線近似,構建無需依靠對手信息的普適防護機制。
OAPA大幅下降了練習本錢,一起具有在不知道或自適應進犯場景下的穩健防護才能,為三維環境下的自動防護供給了一種有用且高效的處理方案。
(4)在多使命與多環境上取得優勝功能,展示優勝的泛化與適應才能
論文在多個規范對立測驗環境與使命中進行了體系評價,試驗成果標明:REIN-EAD在反抗多種不知道和自適應進犯下表現出明顯優于現有被迫防護辦法的功能。
其杰出的泛化才能和對雜亂實際國際場景的適應性,進一步驗證了本文辦法在安全要害體系中的運用潛力。
辦法與理論
REIN-EAD結構
REIN-EAD是一種模仿人類在動態環境中自動感知與反響才能的對立防護結構,該結構(如下圖所示)經過感知模塊與戰略模塊的協同,使體系具有了與環境自動交互、迭代收集信息并增強本身魯棒性的才能。辱 教室 在線播放
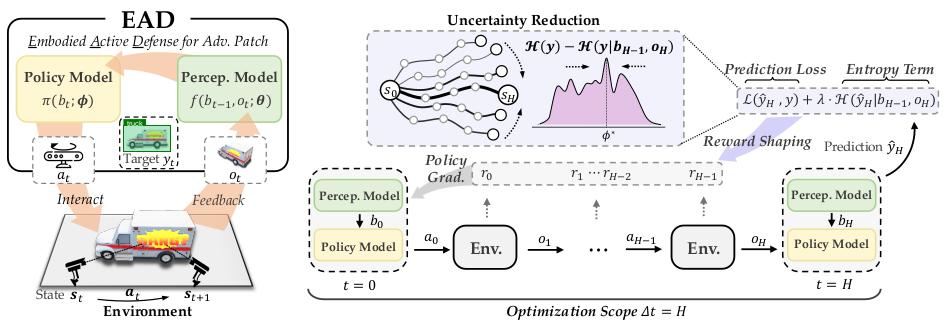
△圖1:REIN-EAD結構
REIN-EAD由兩個中心的循環神經模塊組成,創意來源于支撐人類活潑視覺體系的大腦結構:
感知模型擔任在每一時刻步歸納當時觀測與上一步的內部信仰狀況,生成對環境狀況的增強表征,并據此猜測當時的場景標簽 。該模型經過循環結構充分運用與環境交互取得的序列信息,然后完成對雜亂視覺輸入的魯棒了解;
戰略模型則依據感知模型構建的內部環境了解,生成用于操控下一步感知行為的動作信號,即決議從哪個視角、以何種辦法繼續收集信息,然后有戰略地引導視覺體系履行方針驅動的自動感知使命。
經過感知模型與戰略模型的閉環聯動,REIN-EAD完成了對立防護進程中的“感知—決議計劃—舉動”一體化:
在每一時刻挑選長時刻最優的交互動作,并依據環境反應不斷批改其內部標明,使得模型能從多步交互中獲取最具信息量的觀測反應。
這種自動防護機制突破了傳統靜態防護戰略在魯棒性與適應性方面的瓶頸,明顯進步了體系面臨不知道進犯時的辨認與呼應才能。
依據累計信息探究的強化學習戰略
論文擴展了部分可調查馬爾可夫決議計劃進程(POMDP)結構以正式描繪REIN-EAD結構與環境的相互作用。
場景 下的交互進程用 標明。
這兒 別離標明狀況、動作和觀測空間。場景 下的狀況搬運 契合馬爾可夫性質。
因為環境的部分可調查性,智能體不能直接拜訪狀況,而是接納從調查函數 采樣的調查值。
REIN-EAD的猜測進程是多步條件下的接連觀測和循環猜測,感知與動作循環依靠——感知輔導了動作,而動作又取得更好的感知。
直觀上,能夠經過RNN Style的練習辦法優化多步條件下的EAD結構,但是,該進程觸及沿時刻步反傳梯度,團隊證明了這種做法的缺點。
首要,論文經過理論剖析證明RNN Style的練習辦法本質上是一種貪婪探究戰略:
這種貪婪探究戰略或許導致EAD選用部分最優戰略,難以從多步探究中繼續獲益。
△圖2:貪婪信息探究或許導致重復探究
第二,沿時刻步反傳梯度要求狀況搬運函數和調查函數有必要具有可微分性,該性質在實際環境和常用的仿真引擎(如UE)中都是不滿足的。
最終,在多步條件下反傳梯度需求構建十分長的梯度鏈條,這或許導致梯度消失/爆破,并帶來巨大的顯存開支。
為了處理貪婪戰略的次優性,進步REIN-EAD的功能,論文引進了累積信息探究的界說:
以及多步累積交互方針:
其間, 是探究軌道, 標明時刻步 的猜測丟失, 作為正則化項,標明時刻步 的標簽猜測熵,阻撓智能體做出具有對立特征的高熵猜測。
多步累積交互方針包括最小化猜測丟失的方針項和賞罰高熵猜測的正則項,經過一系列與環境的相互作用,在 步的范圍內優化戰略,最小化方針變量的長時刻不確定性,而不是只專心于單步。
該方針經過一系列舉動和調查來最小化方針變量的不確定性,結合猜測丟失和熵正則化項,鼓舞智能體到達信息豐厚且魯棒的認知狀況,然后對對立擾動具有魯棒性。
論文中對所提出的多步累積交互方針與累積信息探究的界說一致性進行了證明,并進一步剖析了累積信息戰略比較貪婪信息戰略的功能優勝性。
為了進一步消除對可微分練習環境的依靠并下降梯度優化的不安穩性,論文中提出了一種結合了面向不確定性的獎賞塑形的強化戰略學習辦法。
面向不確定性的獎賞塑形在每一步供給密布的獎賞,促進戰略 尋求新的調查成果作為來自環境的反應,處理了多步累積交互方針中的只能在回合結束時取得獎賞的稀少性問題,減輕了探究和運用分配的應戰,促進了更快的收斂和更有用的學習。
論文中還證明了這種獎賞塑辱 教室 在線播放形與多步累積交互方針的等價性(細節拜見論文)。
關于強化學習骨干,論文中選用了學習功率和收斂安穩性較好的近端戰略優化(PPO),經過約束戰略的巨細來完成安穩的戰略更新。

離線對立補丁近似技能
論文中還提出了離線對立補丁近似(OAPA),以處理3D環境中對立練習的核算開支。
對立補丁 的核算一般需求內部最大化迭代,這不只核算貴重,還或許導致防護對特定進犯戰略過擬合,然后阻止模型在不知道進犯中推行的才能。
為了在堅持對立不行知性的一起進步采樣功率,論文在練習REIN-EAD模型之前引進了OAPA,經過預先對視覺骨干進行投影梯度上升得到一組代替的補丁作為對立補丁流形的離線近似。
試驗成果標明,履行這種離線近似最大化答應REIN-EAD模型學習緊湊而賦有表現力的對立特征,使其能夠有用地防護不知道進犯。
此外,因為這種最大化進程只在練習前產生一次,因而大大進步了練習功率,使其與傳統對立練習比較更具有競爭力。
試驗與成果
論文中在人臉辨認、3D物體分類、方針檢測多個使命上運用一系列像素空間、隱變量空間下的白盒、黑盒、自適應進犯辦法,成果標明在三個使命上REIN-EAD的作用都優于SAC、PZ、DOA等基線防護(表1,3,4)。
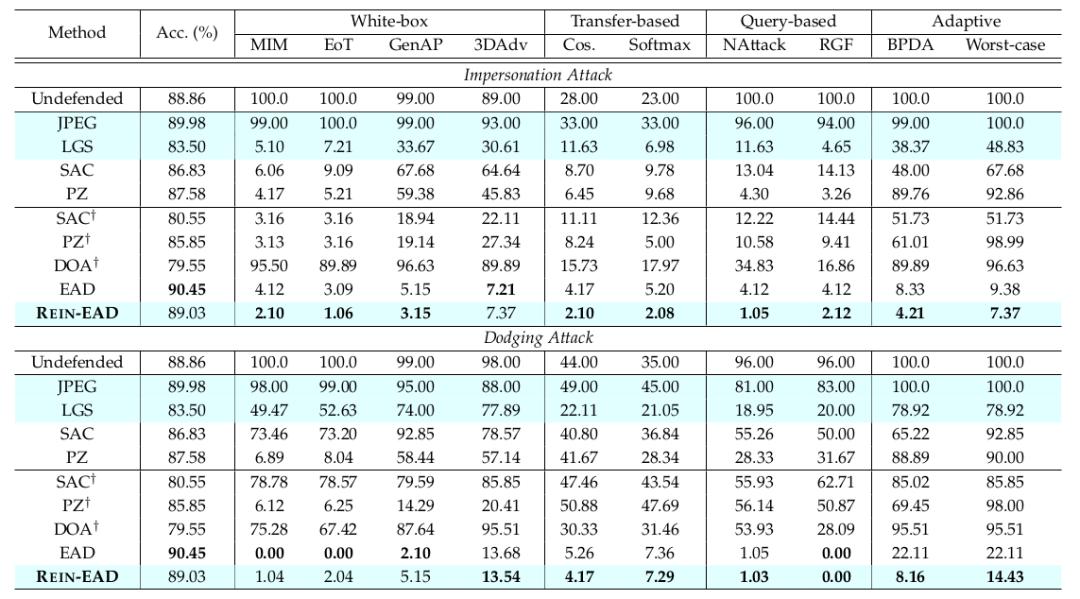
△表1:人臉辨認使命中逃逸和扮演兩種進犯方針下的成果
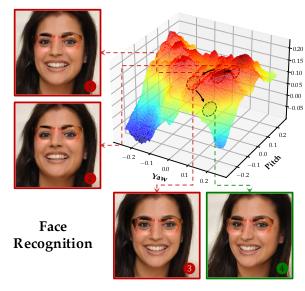
人臉辨認使命中,經過REIN-EAD結構改善IResNet50模型,運用EG3D可微分烘托器完成CelebA-3D數據集的可微分三維重建,以對累計探究的REIN-EAD與ICLR 2024 工作中貪婪探究的EAD進行公正比較。
經過對各個組件的融化,別離證明了累計信息探究和OAPA的有用性(表1,2,圖3)。
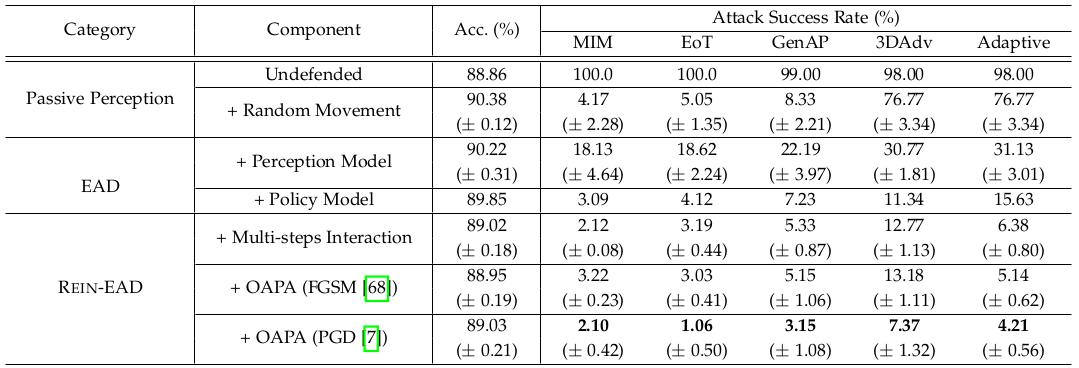
△表2:人臉辨認使命中的REIN-EAD模塊融化成果

△圖3:人臉辨認試驗的REIN-EAD可視化示例
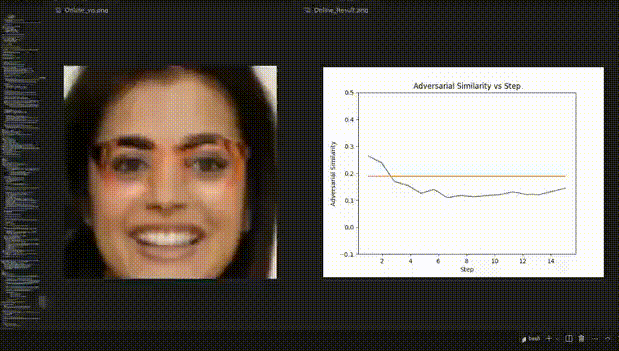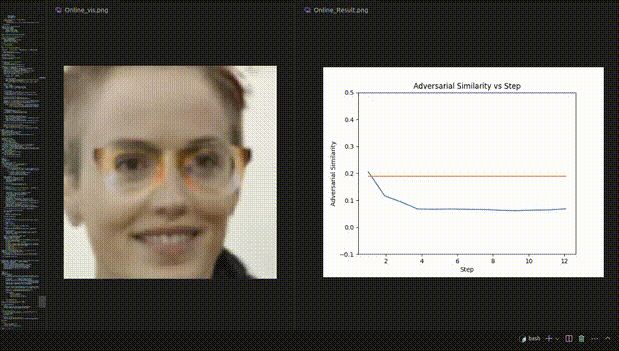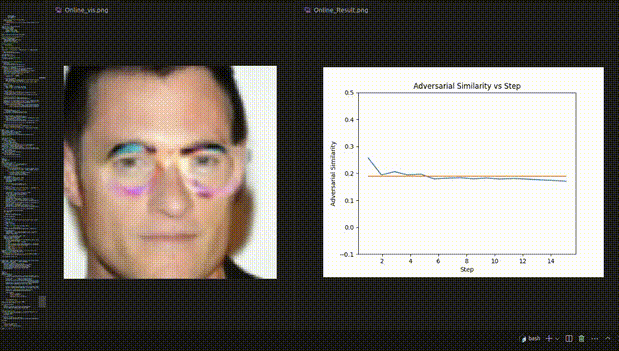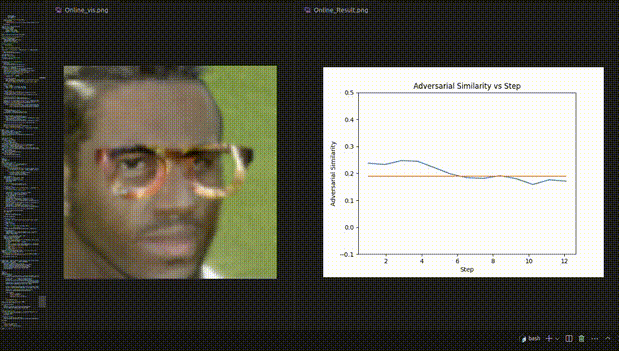
人臉辨認試驗的可視化動態示例
在物體分類使命中,經過REIN-EAD結構改善Swin-S模型,運用Pytorch3D對OmniObject3D三維掃描物體數據集進行可微分烘托,以在三維環境下的圖畫分類使命上對REIN-EAD的通用性進行評價(表3)。
雖然在前期過程中REIN-EAD或許被對立補丁詐騙做出過錯猜測,但在隨后的過程REIN-EAD進行了正確的自我批改(圖4)。
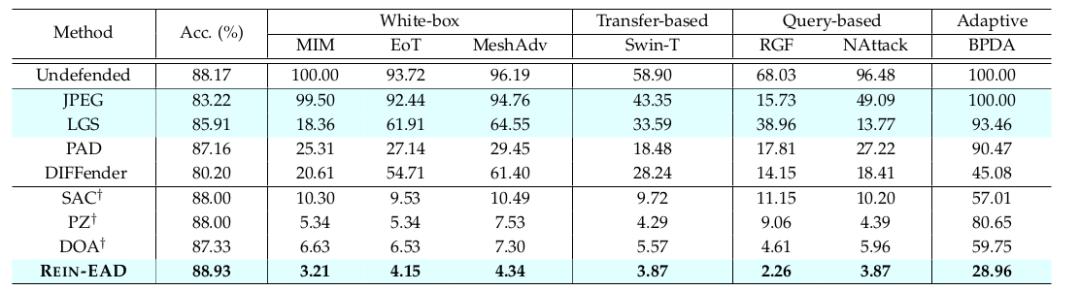
△表3:物體分類試驗成果
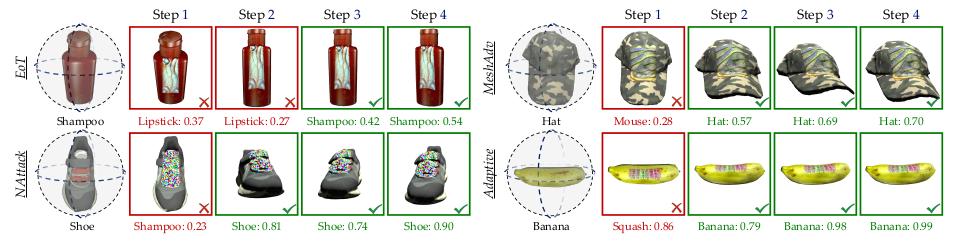
△圖4:物體分類試驗的REIN-EAD可視化示例
方針檢測使命中,經過REIN-EAD結構改善YOLO-v5模型,運用CARLA構建具有實在烘托觀測的試驗場景,進一步證明了REIN-EAD在雜亂使命和實際場景的有用性(表4,圖5)。
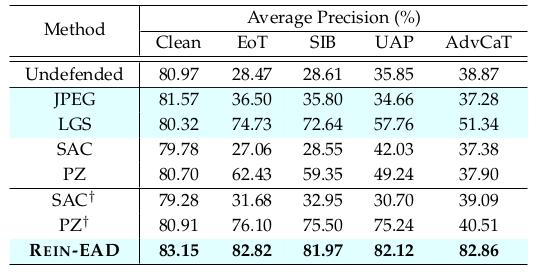
△表4:方針檢測驗驗成果
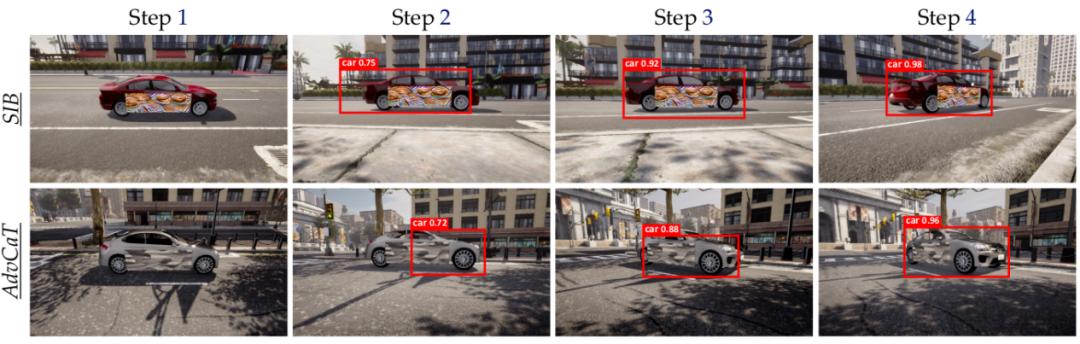
△圖5:方針檢測驗驗的REIN-EAD可視化示例

方針檢測驗驗的可視化動態示例
此外,論文中還對補丁巨細、補丁形狀、進犯強度等多個不同的進犯對手戰略進行了彌補試驗,以全面的驗證REIN-EAD面臨不知道進犯對手的泛化才能。
本文提出的REIN-EAD是一種新的自動防護結構,能夠有用地減輕實際國際3D環境中的對立補丁進犯。
REIN-EAD運用探究和與環境的交互來將環境信息語境化,并改善其對方針目標的了解。
它積累了多步相互作用的時刻一致性,平衡了即時猜測精度和長時刻熵最小化。
試驗標明,REIN-EAD明顯增強了魯棒性和泛化性,在雜亂使命中具有較強的適用性,為對立防護供給了不同于被迫防護技能的新研討視角。
論文:https://arxiv.org/abs/2507.18484
代碼:https://github.com/thu-ml/EmbodiedActiveDefense
本文來自微信大眾號“量子位”,作者:清華朱軍團隊,36氪經授權發布。